Supervisione umana dell'IA
La supervisione umana nei sistemi di IA è un requisito di conformità:
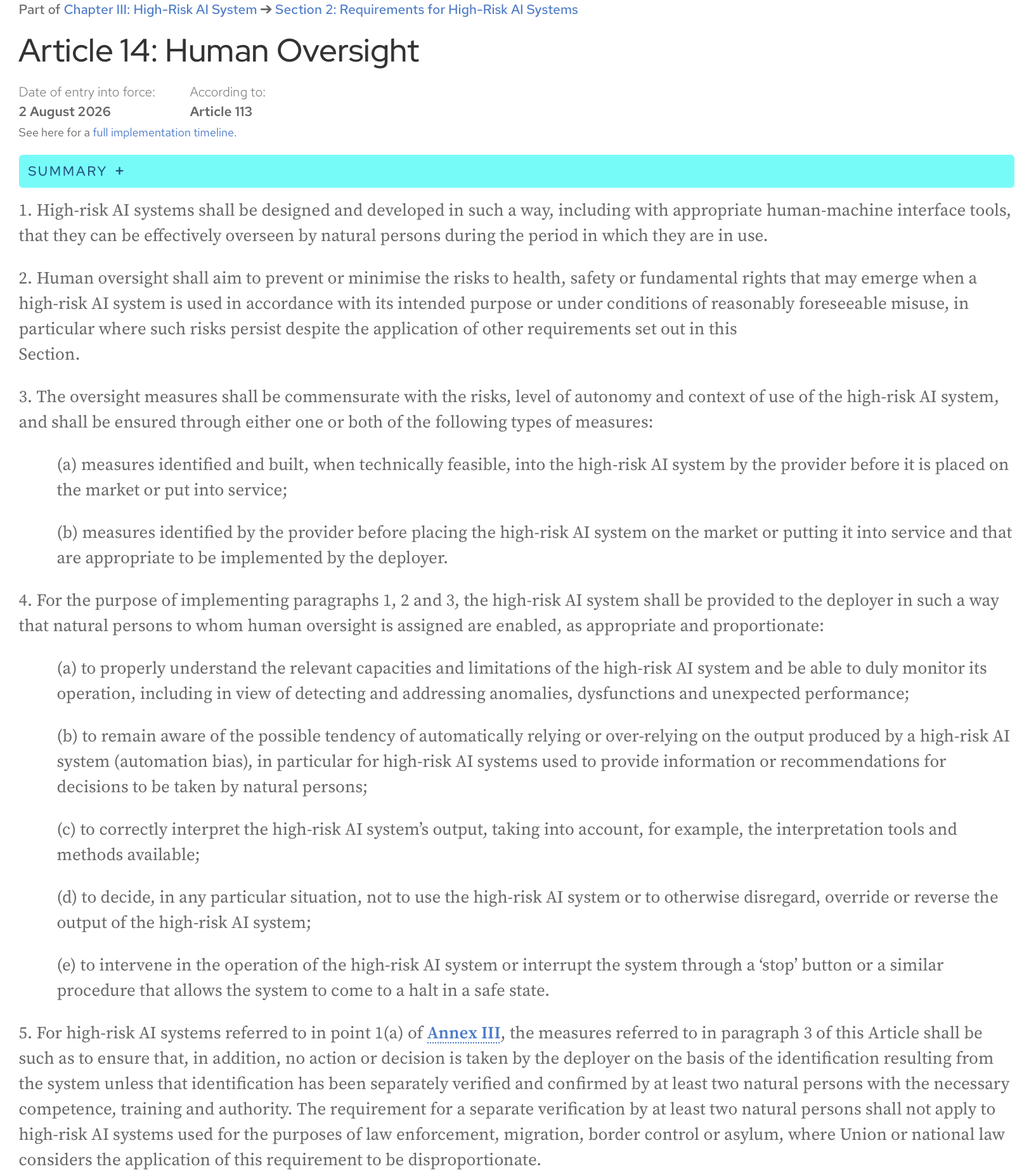
AI Act, Articolo 14: I sistemi di IA ad alto rischio devono essere progettati e sviluppati in modo tale, anche con strumenti di interfaccia uomo-macchina appropriati, da poter essere efficacemente supervisionati da persone fisiche durante il periodo in cui sono in uso.
Ecco il testo completo dell’articolo dalla pagina web ufficiale dell’AI Act:
L’articolo 22 del GDPR prevede esplicitamente per gli individui il diritto “di non essere sottoposti a una decisione basata unicamente sul trattamento automatizzato, compresa la profilazione, che produca effetti giuridici che lo riguardano o che incida in modo analogo significativamente sulla sua persona”. Ciò significa che per qualsiasi sistema decisionale automatizzato che abbia un impatto rilevante su un individuo (ad es. negare una richiesta di prestito, un’offerta di lavoro o un beneficio pubblico), un essere umano deve essere coinvolto nel processo per rivedere e convalidare la decisione. L’individuo ha anche il diritto di contestare la decisione automatizzata e di ottenere l’intervento umano.

E, non a caso, la supervisione umana è un requisito chiave sia nella ISO 42001 che nel NIST AI Risk Management Framework (AI RMF). Entrambi i framework, sebbene diversi nel loro approccio, sottolineano la necessità dell’intervento umano per garantire l’uso responsabile ed etico dei sistemi di IA.
Questo post è la mia interpretazione del paper che è stato presentato alla recente sessione del mensile Data61 AI Adoption and Assurance Chat - “Designing meaningful human oversight in AI” (https://www.researchgate.net/publication/395540553_Designing_Meaningful_Human_Oversight_in_AI).
(la citazione completa del paper: Zhu, Liming & Lu, Qinghua & Ding, Ming & Lee, Sunny & Wang, Chen & Data, & Csiro, & Australia,. (2025). Designing Meaningful Human Oversight in AI. 10.13140/RG.2.2.16624.11528)
Il paper discute il problema con l’approccio attuale alla supervisione umana e presenta consigli pratici per gli sviluppatori di sistemi di IA.
Cos’è la supervisione umana e come viene eseguita?
Il problema con la supervisione umana è che è mal definita. Ma, a mio parere, ciò che rende tutto più complicato è il nostro naturale bias di automazione - una tendenza a fidarsi dell’output di una macchina più del nostro stesso giudizio. Quante volte hai seguito ciecamente un GPS su una strada inesistente?
Di conseguenza, o approviamo l’output del sistema senza comprenderlo adeguatamente (“rubber-stamp” it).
Ad esempio, il sistema di IA di una banca può contrassegnare la tua transazione come ad alto rischio e un analista umano, incaricato di rivedere migliaia di tali avvisi ogni giorno, approva automaticamente la decisione dell’IA e blocca il tuo account.
Anche lo scenario opposto è comune: limitiamo così tanto il sistema che invece di dargli un obiettivo di alto livello e una certa libertà di esplorare compromessi e trovare soluzioni, cerchiamo di pre-programmare ogni singola azione che dovrebbe intraprendere e quindi lo riduciamo a un sistema di automazione basato su regole.
Un’azienda vuole che un chatbot di IA gestisca le richieste dei clienti. Invece di dargli un obiettivo di alto livello come “risolvere il problema del cliente in modo educato ed efficiente”, lo si programma con uno script rigido che impone che se un cliente chiede: “Come posso restituire un prodotto?”, il bot deve rispondere con un link alla pagina dei resi e poi chiedere: “Questa risposta ha risolto la tua domanda?”. Non può gestire domande sfumate come: “Ho perso lo scontrino, posso comunque restituire questo articolo?” perché le regole non coprono quello scenario specifico. Il chatbot perde la sua qualità di agente e diventa un albero decisionale di base e frustrante.
Il paper sostiene che nessuno di questi scenari è ottimale e che l’agire umano e l’agire dell’IA non sono un gioco a somma zero. La collaborazione dei due produce risultati migliori di quanto ciascuno potrebbe ottenere da solo.
Come può essere progettata la supervisione umana per consentire questa collaborazione?
Due tipi di agire
Partiamo dalla definizione di agire: è la capacità di agire e far accadere le cose da soli, per raggiungere un obiettivo.
Il paper suggerisce di distinguere tra i due tipi di agire:
- Agire operativo (la capacità dell’IA di generare soluzioni)
Ad esempio, un sistema di IA medico genera una diagnosi.
- Agire valutativo (la capacità dell’uomo di comprendere, giudicare, verificare la soluzione dell’IA e, se necessario, orientarne i risultati o sostituirli con soluzioni alternative)
Un medico non replica il processo diagnostico. Non è compito di un medico rifare il lavoro dell’IA o superare in astuzia la macchina. Invece, il loro ruolo è valutare la diagnosi dell’IA. Il medico si chiede: “Ha senso? Il ragionamento dell’IA è coerente con ciò che farebbe un esperto umano responsabile?”. Controllano la coerenza. Rivedono la logica dell’IA, che potrebbe essere un elenco di sintomi chiave e una citazione della letteratura medica. Il medico verifica che questo ragionamento sia in linea con la propria formazione e gli standard medici. Aggiungono anche il contesto umano: sapendo che il trattamento per una malattia rara è una terapia costosa, dolorosa e intensiva di un anno, considerano le preferenze del paziente, la situazione finanziaria e se sono disposti a impegnarsi in un regime così difficile. Infine, soppesano i potenziali benefici del trattamento rispetto al suo onere significativo e decidono se è il corso d’azione più appropriato ed etico, anche se la diagnosi dell’IA è tecnicamente corretta.
È difficile non essere d’accordo con l’opinione degli autori secondo cui “valutare” è una parola migliore di “supervisionare” perché enfatizza il ruolo umano come attivo e giudicante, piuttosto che meramente di supervisione o simbolico.
L’agire valutativo fornisce responsabilità
Se qualcosa va storto, un essere umano è in definitiva responsabile. L’IA non può essere ritenuta responsabile in un tribunale; la persona che ha valutato il suo output può. Inoltre, il giudizio dell’essere umano ancora le azioni dell’IA a standard professionali, etici e sociali che l’IA stessa non può comprendere. L’IA può trovare il percorso più veloce, ma solo l’essere umano può decidere se quel percorso è il più etico o sicuro. Questi due vantaggi sono fondamentali per un’IA responsabile e affidabile.
Fedeltà del ragionamento interno vs esterno
Come possiamo valutare gli output di un sistema se non riusciamo ancora a cogliere appieno il complesso funzionamento interno dei moderni modelli di IA? Ogni attivazione di una rete neurale, ogni aggiustamento di un parametro, o come la conoscenza appresa dal modello (come il concetto di “gatto”) è distribuita e immagazzinata all’interno dei suoi milioni o miliardi di parametri (la memoria del modello) - cercare di capire questo circuito algoritmico non è fattibile in questa fase di sviluppo dell’IA, e anche se lo fosse, sarebbe come guardare le decisioni che un programma di scacchi per computer prende attraverso il prisma dei singoli calcoli che fa - troppi dettagli, troppo complessi e non molto utili per valutare effettivamente le decisioni.
Invece, possiamo progettare sistemi in modo tale che forniscano spiegazioni che abbiano senso per un essere umano - spiegazioni basate su ciò che il paper definisce “fedeltà del ragionamento esterno” o “plausibilità”. Un programma di scacchi direbbe: “Ho scelto questa mossa per controllare il centro della scacchiera e mettere pressione sul cavallo dell’avversario”, e saremmo in grado di valutare questa decisione perché la sua spiegazione è in linea con i principi consolidati degli scacchi e il giudizio umano.
Ora, come progettiamo un sistema per fornire tali indizi che possiamo valutare e, se necessario, contestare?
Asimmetria risoluzione-verifica
Il paper introduce un utile concetto di asimmetria risoluzione-verifica: la difficoltà di creare una soluzione (risolvere) e la difficoltà di controllare quella soluzione (verificare) spesso non sono uguali. Questo è il caso sia in fase di progettazione che in fase di esecuzione, e comprenderlo aiuta a creare un efficace processo di supervisione umana.
Nella fase di progettazione, il compito di “risolvere” è lo sforzo richiesto per costruire il sistema di IA:
- creazione dell’architettura di sistema
- specificazione degli obiettivi
- implementazione del sistema
- progettazione di compiti di verifica e soglie da applicare a molte istanze future
Il compito di “verificare” è lo sforzo per valutare e convalidare quel sistema prima che venga distribuito:
- revisione dei requisiti
- valutazione dell’architettura e del design
- test
- altre forme di verifica e convalida
In fase di esecuzione, esaminiamo le singole istanze - output specifici del sistema, soluzioni specifiche che suggerisce. Il compito di “verificare” qui è valutare questi singoli output. A volte i compiti di “risolvere” sono molto costosi dal punto di vista computazionale ma controllare gli output è facile; tuttavia, ci sono casi in cui l’IA genera rapidamente un output ma l’essere umano che supervisiona il sistema impiegherà molto tempo e sforzi per verificarlo (ad esempio, verifica dei fatti, revisione per bias, garanzia di allineamento dei contenuti con gli standard e così via), e la verifica diventa un collo di bottiglia.
La conclusione principale è che una supervisione efficace deve adattarsi a questa asimmetria.
Quando la verifica in fase di progettazione è facile
Questa strategia consiste nel integrare la sicurezza fin dall’inizio. Caricando frontalmente il processo di verifica, è possibile individuare potenziali problemi prima ancora che l’IA venga messa in uso, riducendo la necessità di un monitoraggio costante e manuale.
Ad esempio, il braccio di un robot di fabbrica deve operare con un alto grado di precisione e sicurezza, rimanendo sempre all’interno della sua area di lavoro designata. La verifica che non danneggerà un lavoratore umano nelle vicinanze viene eseguita durante la fase di progettazione e programmazione attraverso test approfonditi, modellazione e parametri di sicurezza pre-programmati. L’obiettivo è garantire che il sistema sia “sicuro per progettazione”, rendendo superfluo l’intervento umano in tempo reale nei suoi movimenti di base.
Quando la verifica in fase di progettazione è difficile
Questo paper riconosce che alcuni compiti di IA sono troppo complessi per essere completamente verificati durante lo sviluppo. In questi casi, il sistema può essere progettato per fornire informazioni chiare e attuabili a un operatore umano, che può quindi prendere una decisione finale informata. L’essere umano funge da punto di controllo finale.
Ad esempio, un sistema di IA che raccomanda una diagnosi sta eseguendo un compito molto complesso. La sua accuratezza può essere difficile da verificare completamente durante lo sviluppo a causa delle infinite variazioni nell’anatomia e nelle malattie umane. Pertanto, il sistema dovrebbe essere progettato per facilitare la verifica in fase di esecuzione: non si limiterà a fornire una diagnosi, ma fornirà anche un punteggio di confidenza (ad es. “probabilità del 95% di un tumore benigno”), evidenzierà le aree specifiche di una scansione che hanno portato alla sua conclusione, aggiungerà altre citazioni pertinenti e offrirà una spiegazione dettagliata del suo ragionamento (tracce di logica). Un medico può quindi utilizzare queste informazioni per formulare la diagnosi finale e informata.
E per quanto riguarda i domini soggettivi dove non c’è una risposta giusta?
In aree come l’arte, l’etica o la pianificazione strategica, persone diverse hanno valori e prospettive diverse. Qui, invece di avere un sistema di IA che “collassa” tutta la diversità in un’unica risposta “corretta” dove spesso non ce n’è una, dovremmo progettare l’IA per essere un partner in una discussione. L’obiettivo non è ottenere una soluzione perfetta, ma far emergere diverse prospettive e scenari. Questo approccio rende il disaccordo una parte preziosa del processo, poiché l’IA può mostrarti i vari compromessi e punti di vista. In questo modo, il sistema diventa più responsabile, perché costringe te, l’essere umano, a considerare attivamente queste opzioni e a prendere una decisione ponderata e ben motivata basata su tutti gli angoli disponibili.
Confine della delega
Gli autori del paper sottolineano che esiste una linea oltre la quale l’IA non dovrebbe più essere il principale decisore - la chiamano “confine della delega”. In alcuni campi ad alto rischio come la condanna legale, la diagnosi medica o l’assunzione, il giudizio finale ha un peso etico e normativo significativo. Queste decisioni non dovrebbero essere delegate interamente all’IA. In questi casi, la supervisione non consiste solo nel controllare se l’output dell’IA è corretto. Si tratta di salvaguardare la responsabilità umana. L’IA dovrebbe agire come uno strumento per supportare il decisore umano, fornendo dati e approfondimenti, ma senza mai sostituire completamente il loro ruolo. La decisione finale deve rimanere a un essere umano per garantire la responsabilità etica e morale.
Le 3 C di una supervisione umana efficiente
Cosa dobbiamo raggiungere quando progettiamo il processo di supervisione dell’IA?
- Controllo (noi umani possiamo intervenire tempestivamente ed efficacemente per mettere in pausa, reindirizzare o sostituire una decisione di un’IA)
- Contestabilità (le decisioni dell’IA sono supportate da ragioni e prove comprensibili, in modo che possano essere riviste e contestate)
- Competenza (la supervisione migliora le prestazioni complessive e l’equità del sistema, evitando override bruschi che degraderebbero gli output corretti dell’IA)
Condizioni di agire e supervisione
Il paper fa riferimento alle condizioni di agire (individualità, fonte dell’azione, orientamento all’obiettivo e adattabilità) come un quadro per progettare una supervisione umana efficace sia in fase di progettazione che in fase di esecuzione. Puoi leggere di più su queste condizioni in un altro paper - Agency is Frame-Dependent
Esaminiamo ciascuna di queste condizioni - e i consigli pratici di progettazione della supervisione umana relativi a ciascuna di esse che il paper offre agli sviluppatori di sistemi.
Individualità
Questa condizione richiede un confine chiaro tra il ruolo dell’IA (agire operativo) e il ruolo dell’uomo (agire valutativo). Qui dobbiamo creare il progetto per l’interazione uomo-IA in cui l’IA dovrebbe essere libera di lavorare autonomamente e l’uomo dovrebbe intervenire solo in punti di controllo specifici e ben definiti. Offuscare questi confini diffonde la responsabilità.
Fase di progettazione
- Definire i confini del sistema e impostare punti di passaggio espliciti per l’intervento umano.
Dove finisce il lavoro dell’IA? Non solo “Il sistema gestirà il servizio clienti”, ma “Il sistema risponderà alle domande dei clienti relative alle specifiche del prodotto da una base di conoscenza predefinita. Non gestirà controversie di fatturazione o rimborsi”.
- Aggiungere condizioni per l’astensione (il rifiuto di rispondere a una query) quando il sistema deve segnalare un caso per l’intervento umano invece di indovinare
Ad esempio, quando il punteggio di confidenza < 90% il sistema segnalerà a un essere umano che sta operando in una “zona grigia”.
- Definire punti di passaggio umani predeterminati - dove il controllo passa dall’IA a un essere umano.
Non si tratta solo di un basso punteggio di confidenza, ma della significatività dell’azione stessa. Ad esempio, anche se un’IA è sicura al 99%, se la decisione comporta una transazione finanziaria superiore a 1 milione di dollari o una diagnosi medica critica, la natura ad alto rischio del compito lo rende un punto di controllo umano obbligatorio. Ecco un esempio di come il passaggio di consegne umano può essere implementato negli agenti di MS Copilot:
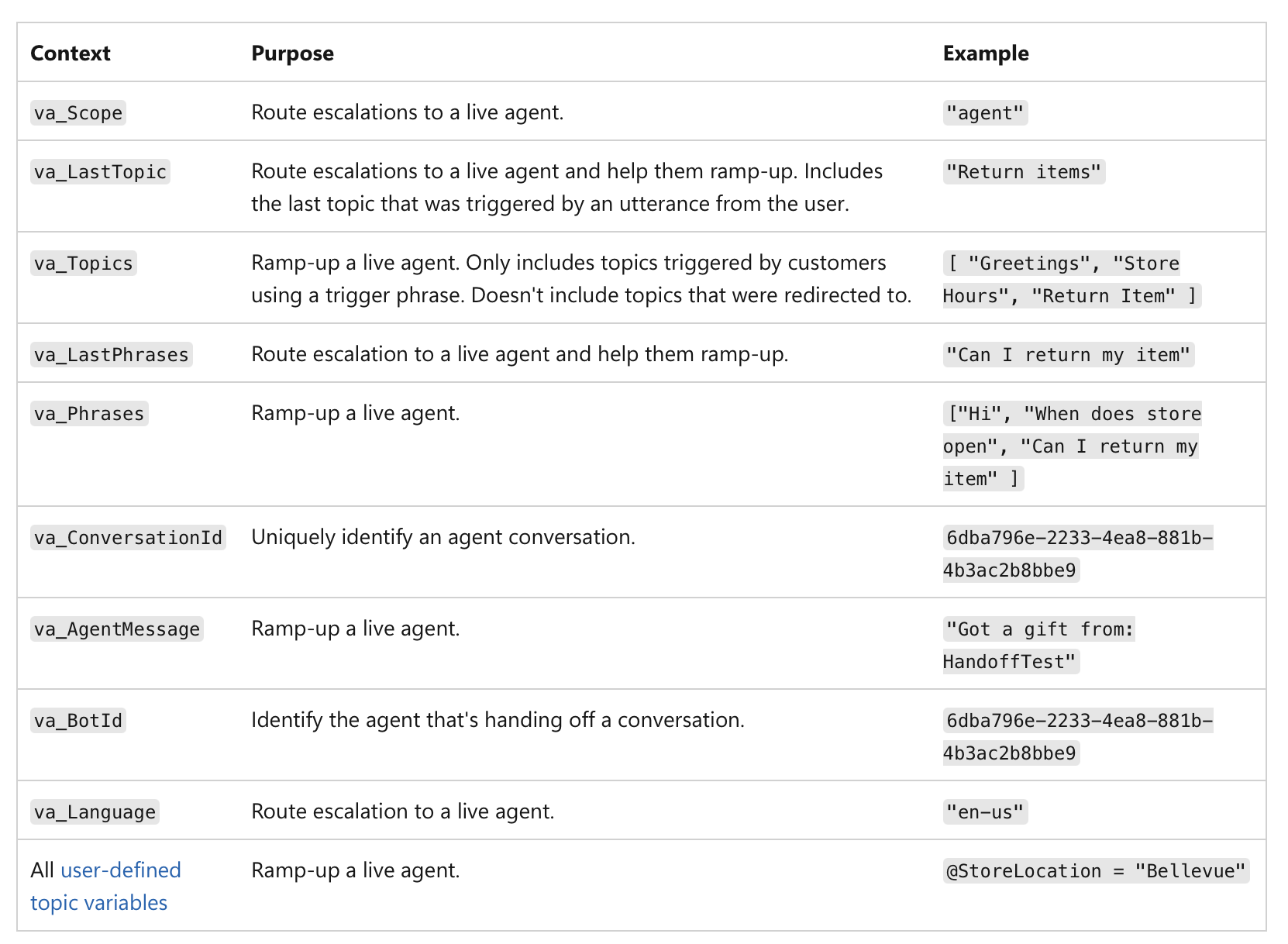 (fonte)
(fonte)
Fase di esecuzione
Una volta che il sistema è attivo, l’attenzione si sposta sulla registrazione e sulla responsabilità.
- Registrare quando il controllo passa effettivamente dall’IA all’uomo.
Il tuo sistema deve creare un record immutabile (ad es. su una blockchain o un database a scrittura unica - per impedire manomissioni) di ogni passaggio di consegne: il registro dovrebbe includere un timestamp, l’azione finale dell’IA e l’identità dell’umano che ha preso il controllo:
“Richiesta di prestito #12345 consegnata all’analista umano Mary Smith alle 10:30 a causa di un punteggio di credito inferiore alla soglia.”
Ciò garantisce una chiara responsabilità per la decisione finale.
I dati registrati possono essere utilizzati per creare dashboard e report per la supervisione: puoi vedere con quale frequenza si verifica l’intervento umano, se le raccomandazioni dell’IA vengono accettate o rifiutate e chi prende le decisioni finali. Questo ci aiuta a identificare le aree in cui le prestazioni dell’IA potrebbero essere deboli o dove i processi umani necessitano di perfezionamento.
Fonte dell’azione
Qui tracciamo la causa di un output. Il processo generativo di un’IA è spesso opaco, quindi cercare di “co-possederlo” creando meticolosamente prompt può essere solo un’illusione di controllo. Invece, la supervisione umana dovrebbe concentrarsi sulla valutazione dell’output finale rivedendo la storia causale (prompt, input, chiamate IA) (alias provenienza).
Fase di progettazione
-
Assicurarsi che il sistema possa catturare un record completo della sua provenienza attraverso la registrazione end-to-end (immutabile e standardizzata per la leggibilità da parte della macchina), in cui ogni passo nel flusso di lavoro dell’IA viene automaticamente registrato e dotato di timestamp:
- dati di input e prompt utilizzati
- versione specifica del modello di IA utilizzato per generare l’output
- cronologia completa delle istruzioni e delle modifiche umane
- eventuali chiamate esterne, servizi esterni, API, database a cui il sistema di IA ha avuto accesso
- output intermedi che il sistema ha generato ma che ha finito per scartare
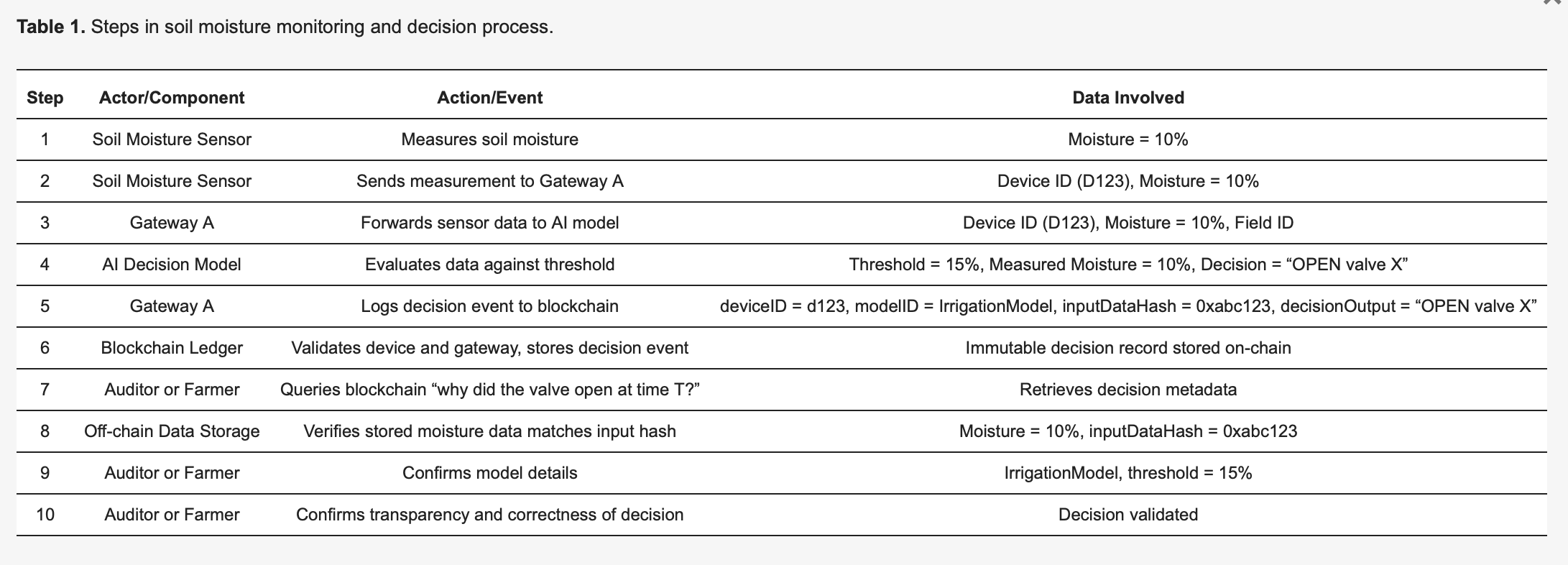
Questa pre-stampa di “Using Blockchain Ledgers to Record the AI Decisions in IoT”, ad esempio, discute come questo può essere fatto in pratica: https://www.preprints.org/manuscript/202504.1789/v1 Ecco un esempio da questa pre-stampa:
Per rendere concreta la metodologia, si consideri un sistema di irrigazione intelligente basato su IoT [27], dettagliato nella Tabella 1. I sensori di umidità del suolo (dispositivi) inviano letture a un modello di IA edge che decide se le valvole dell’acqua debbano aprirsi o rimanere chiuse. Ogni decisione presa dall’IA attiva un evento di registrazione catturato immutabilmente su un registro blockchain, migliorando la trasparenza e la verificabilità. Come illustrato nella Tabella 1, il Sensore 123 rileva un’umidità del 10 percento e trasmette questa misurazione al Gateway A. Il Gateway A inoltra i dati al modello di IA, che, a causa di una soglia predefinita del 15 percento (specificata da IrrigationModelv2), determina l’azione appropriata: “valvola = APERTA” per il campo X. Il Gateway A prepara quindi una transazione contenente metadati critici - inclusi deviceID (123), modelID (IrrigationModelv2), un hash dei dati di input (0xabc123) e l’esito della decisione (valvola APERTA X) - la firma e la invia alla blockchain. I nodi della blockchain verificano l’autenticità e le autorizzazioni del Sensore 123 e del Gateway A, confermano che sono correttamente registrati per il campo X e successivamente memorizzano il record in modo permanente. Viene emesso un evento per indicare la registrazione riuscita. Successivamente, un revisore o l’agricoltore può chiedere “perché è stata rilasciata acqua al tempo T?”, recuperando il record dettagliato della transazione dalla blockchain. L’hash (0xabc123) dalla blockchain può quindi essere confrontato con i dati dei sensori archiviati off-chain (archiviati su IPFS o nel database del Gateway A) per confermare che la lettura dell’umidità era effettivamente del 10 percento. Inoltre, facendo riferimento al registro dei modelli, l’agricoltore può convalidare che la soglia di irrigazione era impostata al 15 percento di umidità, confermando che la decisione dell’IA era corretta e giustificata. Questo processo strutturato migliora significativamente la trasparenza: ogni azione automatizzata è verificabile e completamente spiegabile attraverso metadati registrati e l’immutabilità della blockchain garantisce che né gli operatori agricoli né i produttori di dispositivi possano modificare segretamente i registri delle decisioni.
Fase di esecuzione
- Ispezionare la catena causale per il caso specifico per vedere come è stato generato l’output.
- Utilizzare un dashboard visivo che mappa l’intera catena causale per un output specifico per vedere il risultato finale e ogni passo che ha portato ad esso.
Quando si desidera rivedere una decisione, è possibile richiamare il record di provenienza per quel caso specifico. Non è necessario comprendere il “percorso generativo” interno dell’IA (la matematica complessa e le attivazioni neurali). Invece, si controllano i metadati di provenienza per rispondere a domande come queste:
“Sono stati utilizzati i dati giusti?”
Ad esempio, quando un medico richiama il record di provenienza, i metadati mostrano un elenco dei punti dati specifici utilizzati dall’IA. Il record di provenienza conferma che l’IA ha utilizzato la storia medica completa del paziente, un recente esame del sangue del 24/10/25 e una risonanza magnetica del 26/10/25, e tutti i punti dati corrispondono al cartellino sanitario elettronico ufficiale. In un caso diverso, il medico può concludere che il record di provenienza mostra che l’IA ha avuto accesso ai dati degli esami del sangue di due anni fa, ma la cartella del paziente è stata aggiornata con nuovi risultati la scorsa settimana e l’IA ha utilizzato informazioni obsolete.
“Il prompt dell’umano è stato elaborato correttamente?”
Il prompt del medico all’IA era “Analizza i sintomi e raccomanda una diagnosi per un uomo di 45 anni con tosse persistente e febbre”. Il record di provenienza registra la query esatta ricevuta dall’IA. Il medico la confronta con il suo input originale e nota che la query registrata mostra che il prompt è stato troncato, mancando il sintomo “febbre” - quindi l’IA ha elaborato solo “tosse persistente”, il che ha portato a un percorso diagnostico diverso.
“È stata distribuita la versione corretta del modello?”
Il record di provenienza può mostrare che la diagnosi è stata generata da una versione precedente del modello che avrebbe dovuto essere dismessa a causa di un errore di sistema.
Qui, il sistema attribuisce chiaramente le azioni o alla generazione autonoma dell’IA o a un intervento specifico di un essere umano. Ciò consente una chiara responsabilità. Se viene presa una decisione sbagliata, un rapido controllo del registro di provenienza può rivelare se si è trattato di un output difettoso dell’IA o di un errore di valutazione umano, evitando il “gioco delle colpe” in cui l’agire è diffuso.
Orientamento all’obiettivo
L’IA dovrebbe gestire i sotto-obiettivi di basso livello, mentre gli esseri umani mantengono l’autorità sugli obiettivi di alto livello. Il ruolo dell’essere umano è garantire che il percorso scelto dall’IA sia in linea con obiettivi e vincoli più ampi come i requisiti legali o gli obiettivi di equità.
Fase di progettazione
- Pubblicare esplicitamente gli obiettivi di alto livello, i vincoli e le regole di compromesso per l’IA.
Gli obiettivi di primo livello, definiti dall’uomo, sono resi chiari e accessibili. Non si tratta solo di vaghe dichiarazioni di intenti; sono obiettivi tangibili, spesso numerici. Per un’IA logistica, questo potrebbe essere “ridurre al minimo i tempi di consegna del 15% senza aumentare i costi del carburante”. Per un’IA per le assunzioni, un obiettivo di primo livello potrebbe essere “aumentare le candidature qualificate del 20% garantendo al contempo l’assenza di pregiudizi razziali o di genere nell’approvvigionamento dei candidati”.
- Definire vincoli e regole di compromesso.
L’autorità umana si esprime attraverso confini e regole. All’IA dovrebbero essere dati limiti espliciti che non può violare. Ad esempio, “rimanere entro il budget legale”, “non raccomandare alcuna azione che violi le leggi sulla privacy” o “dare priorità all’equità rispetto alla pura efficienza”. Nei casi in cui gli obiettivi sono in conflitto (ad es. velocità vs. costo), le regole di compromesso definite dall’uomo devono dettare quale ha la priorità.
Fase di esecuzione
Qui l’attenzione si sposta sul monitoraggio e sulla valutazione. Un essere umano non ha bisogno di conoscere ogni singolo passo computazionale, ma può vedere se la direzione generale dell’IA è in linea con l’obiettivo di livello superiore. Possiamo valutare i progressi in punti predefiniti specifici.
- Verificare se l’output corrente e i sotto-obiettivi dell’IA sono coerenti con quegli obiettivi dichiarati.
Ad esempio, a un’IA finanziaria potrebbe essere consentito di eseguire più simulazioni per ottimizzare un portafoglio (sotto-obiettivi), ma un analista umano deve approvare la strategia finale per garantire che sia in linea con la tolleranza al rischio e i requisiti legali del cliente (obiettivi di primo livello). Questo processo consente all’IA di utilizzare il suo “agire operativo” per esplorare soluzioni, mentre l’essere umano mantiene l‘“agire valutativo” per garantire che la direzione dell’IA rimanga legittima.
- Assicurarsi che il sistema sia progettato per monitorare e riferire continuamente sui suoi progressi verso i suoi sotto-obiettivi.
Per un’IA di generazione di contenuti, ciò potrebbe comportare la segnalazione dei suoi tentativi di trovare parole chiave specifiche o la sua strategia per strutturare l’articolo.
- Il sistema dovrebbe creare un registro chiaro e tracciabile delle sue decisioni, incluso il motivo per cui ha perseguito un particolare sotto-obiettivo. Questo registro viene messo a disposizione di un valutatore umano.
Se un’IA genera un risultato distorto, un revisore può tracciare il suo percorso e vedere dove ha iniziato a deviare dai vincoli di equità definiti nella fase di progettazione.
Adattabilità
Un essere umano non può supervisionare in modo fattibile ogni piccola modifica interna che un’IA apporta. La supervisione umana dovrebbe essere mirata a cambiamenti significativi, come cambiamenti di politica o comportamento generale del sistema. Si tratta di creare le barriere per il comportamento adattivo dell’IA.
Fase di progettazione
- Impostare controlli delle modifiche e monitor di deriva che rilevano cambiamenti comportamentali significativi.
Il sistema dovrebbe essere progettato per versionare i propri modelli e configurazioni per rendere possibile il ripristino a una versione precedente e stabile se qualcosa va storto.
I monitor di deriva sono strumenti che tracciano costantemente le prestazioni e il comportamento dell’IA nel mondo reale. Non misurano solo l’accuratezza; cercano la deriva del concetto (quando la relazione tra i dati di input e di output cambia) e la deriva dei dati (quando i dati di input stessi cambiano). I monitor sono impostati con soglie specifiche. Ad esempio, il monitor di deriva di un’IA per il rilevamento di frodi potrebbe essere impostato per avvisare un essere umano se il suo tasso di falsi positivi aumenta di oltre il 5%.
Fase di esecuzione
Una volta che il sistema è attivo, gli esseri umani non lo osservano costantemente. Vengono avvisati dai monitor automatici, il che consente loro di concentrare la loro attenzione in modo efficace. Quando la soglia di un monitor di deriva viene superata, invia automaticamente un avviso a un team umano. L’avviso dovrebbe includere un’istantanea del comportamento osservato e i dati pertinenti, in modo che l’essere umano possa valutare rapidamente la situazione. Il sistema può anche essere pre-programmato per seguire un protocollo specifico quando viene rilevata una modifica.
Cosa ottengo se implemento questo framework?
Questo approccio crea una potente partnership in cui il sistema di IA e l’essere umano “supervisore” hanno ciascuno un ruolo distinto e prezioso. L’IA è libera di usare la sua potenza di calcolo per affrontare problemi complessi (il suo “agire operativo”), mentre l’essere umano, usando segnali chiari dal sistema, è autorizzato a prendere decisioni informate e di alto livello e a intervenire quando necessario (il suo “agire valutativo”). Il risultato è una collaborazione “a somma non zero”, in cui lo sforzo combinato porta a risultati migliori di quanto l’essere umano o l’IA potrebbero ottenere da soli.
In che modo questo framework affronta l’Art.14 dell’AI Act?
Il framework affronta direttamente i requisiti dell’AI Act dell’UE, in particolare l’articolo 14, offrendo un approccio pratico e attuabile alla “supervisione umana efficace” che va oltre i principi astratti. Definisce la supervisione non come un obbligo vago, ma come un processo sistematico di progettazione dell’IA per supportare l’agire valutativo umano.
Cosa richiede l’AI Act agli sviluppatori di sistemi di IA?
- “Strumenti di interfaccia uomo-macchina appropriati… possono essere efficacemente supervisionati.”
Il principio fondamentale del framework è che il sistema di IA stesso deve essere costruito per consentire la supervisione. Il framework proposto dal paper offre caratteristiche di progettazione fondamentali che garantiscono che il funzionamento del sistema sia trasparente e gestibile per un essere umano.
- “Mirare a prevenire o minimizzare i rischi.”
L’enfasi del framework sull’agire valutativo affronta direttamente questo punto. Il ruolo dell’essere umano è fornire il “giudizio di ordine superiore” che ancora le azioni dell’IA a standard professionali e sociali. Questo è il meccanismo per prevenire i rischi che l’IA, operando con il suo agire operativo, potrebbe non rilevare. I controlli in fase di progettazione del framework (ad es. impostazione di obiettivi di equità, identificazione di decisioni ad alto rischio) garantiscono che la prevenzione dei rischi sia una parte intenzionale dell’architettura del sistema, non un ripensamento.
- “Misure… integrate nel sistema di IA ad alto rischio.”
L’intera struttura del framework è costruita attorno a questo requisito. Gli “Artefatti dell’IA da esporre” e la “Superficie di verifica del sistema” per ogni condizione sono esempi di misure che sono “integrate… nel sistema di IA ad alto rischio dal fornitore”.
La condizione di individualità richiede che il sistema sia progettato con chiari contratti API di passaggio di consegne. La condizione di Adattabilità richiede monitor di deriva e meccanismi di rollback integrati. Queste sono tutte misure concrete implementate dal fornitore.
Il framework guida anche il fornitore nell’identificazione delle misure per l’implementatore. Ad esempio, la condizione Fonte dell’azione richiede al fornitore di fornire all’implementatore un dashboard di provenienza, che è una misura chiave per l’implementatore da implementare e utilizzare.
- “Supervisione umana… abilitata, se del caso e proporzionata.” Il framework traduce direttamente ogni punto di questo sotto-articolo in un requisito di progettazione.
a) “Comprendere adeguatamente le capacità e i limiti pertinenti”
Le condizioni Individualità e Orientamento all’obiettivo affrontano questo punto richiedendo una documentazione esplicita dei confini, degli obiettivi e dei vincoli dell’IA. Ciò fornisce all’essere umano una chiara comprensione delle capacità dell’IA.
b) “Rimanere consapevoli del… bias di automazione”
Il framework promuove l’agire valutativo come contrappeso al bias di automazione. L’enfasi sul controllo degli output dell’IA piuttosto che sulla semplice accettazione costringe l’essere umano a rimanere impegnato e fornisce un meccanismo per scavalcare l’IA quando necessario.
c) “Interpretare correttamente l’…output”
La condizione Fonte dell’azione garantisce che l’output dell’IA sia accompagnato da metadati interpretabili e record di provenienza. Ciò consente all’essere umano di interpretare correttamente il contesto e la catena causale dell’output, rendendo possibile un semplice giudizio.
d) “Decidere… di non usare… o ignorare… l’output”
La condizione Individualità supporta direttamente questo richiedendo punti di passaggio espliciti e meccanismi di “rifiuto di rispondere e passaggio a un essere umano”, autorizzando l’essere umano a intervenire e scavalcare il sistema.
e) “Intervenire… o interrompere… tramite un pulsante ‘stop’”
I meccanismi di rollback e astensione della condizione Adattabilità forniscono l’equivalente funzionale di un pulsante “stop”. Consentono a un essere umano di arrestare o ripristinare l’operazione dell’IA in modo sicuro e controllato.
f) “Verifica da parte di almeno due persone fisiche.”
Il framework fornisce gli strumenti per rendere questo un processo fattibile e significativo. Il record di provenienza della condizione Fonte dell’azione e un registro chiaro di tutte le interazioni umane rendono facile per due o più individui verificare in modo indipendente l’identificazione di un’IA. Entrambi possono richiamare lo stesso set di dati registrati e rivedere la catena causale per raggiungere un consenso, garantendo che la verifica si basi su prove oggettive piuttosto che su congetture soggettive.
Sfide
Naturalmente, sebbene il framework sembri molto promettente e applicabile, il paper non ignora gli svantaggi comuni dell’implementazione dei meccanismi di supervisione.
Complessità e costi
In primo luogo, non tutti sono semplici da configurare: molti richiedono un notevole sforzo iniziale per la progettazione e la costruzione. È necessaria un’esperienza specializzata per creare sistemi in grado di generare logiche strutturate, catturare la provenienza o codificare regole sfumate in un registro degli obiettivi. Inoltre, preparati a costi continui per la manutenzione del sistema, la calibrazione dei segnali e la formazione dei revisori umani sui nuovi processi.
Dipendenza dal segnale
L’efficacia di questi meccanismi di supervisione dipende fortemente dalla qualità dei segnali che producono. Se l’IA genera segnali scarsi o rumorosi (ad es. punteggi di confidenza imprecisi, logiche vaghe o dati di provenienza difettosi), può fuorviare il revisore umano e minare l’intero processo di supervisione.
Onere della verifica
Sebbene l’obiettivo sia migliorare l’efficienza, questi sistemi non eliminano completamente il carico di lavoro umano. In casi limite, nuovi o ambigui, il revisore umano potrebbe comunque dover eseguire controlli a campione intensivi e manuali. Il paper osserva che ciò può ridurre i guadagni di efficienza, poiché i revisori potrebbero dover dedicare molto tempo a risolvere le astensioni o a contestare i suggerimenti dell’IA. L’onere umano si sposta da una valutazione su vasta scala a una verifica dettagliata del lavoro dell’IA, che può comunque essere significativa.
Ricorda: è necessario un cambio di mentalità
Quindi, non è sufficiente dire semplicemente che abbiamo bisogno di “supervisione umana”. Per renderla una realtà, dobbiamo cambiare la nostra mentalità dal semplice “supervisionare l’IA” a progettare l’IA per la collaborazione uomo-IA: ridefinire il ruolo dell’essere umano come valutatore attivo, integrare la supervisione nella progettazione dell’IA, ricordare le tre C - controllo, contestabilità e competenza - e allora non solo rispetterai le normative come l’AI Act, ma creerai un sistema più affidabile e potente che funziona con le persone.
