Menschliche Aufsicht bei KI
Menschliche Aufsicht in KI-Systemen ist eine Compliance-Anforderung:
KI-Gesetz, Artikel 14: Hochrisiko-KI-Systeme müssen so konzipiert und entwickelt werden, auch mit geeigneten Mensch-Maschine-Schnittstellen, dass sie von natürlichen Personen während ihrer Nutzungsdauer wirksam überwacht werden können.
Hier ist der vollständige Text des Artikels von der offiziellen Webseite des KI-Gesetzes:
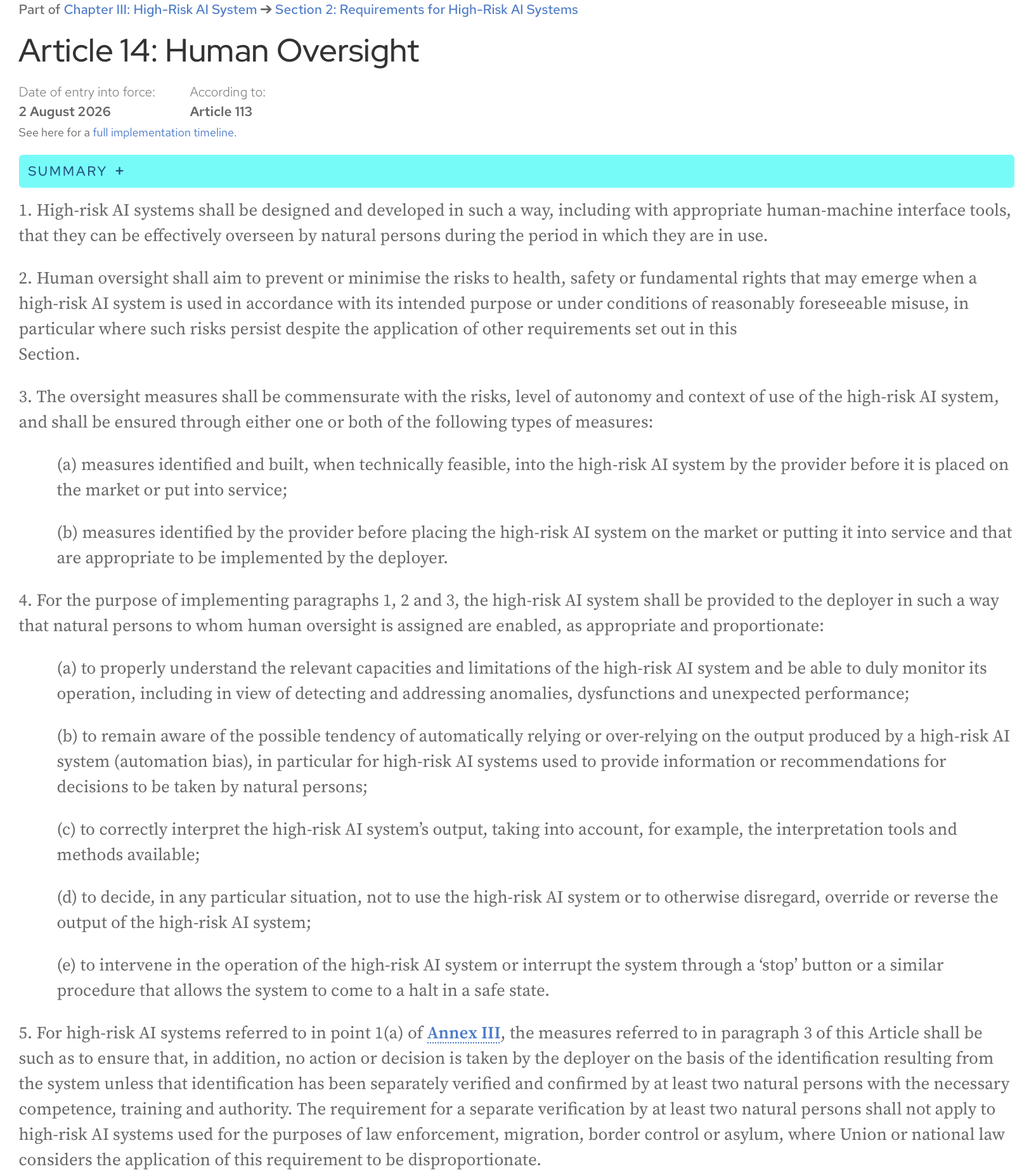
Artikel 22 der DSGVO gibt Einzelpersonen ausdrücklich das Recht, „nicht einer ausschließlich auf einer automatisierten Verarbeitung – einschließlich Profiling – beruhenden Entscheidung unterworfen zu werden, die ihr gegenüber rechtliche Wirkung entfaltet oder sie in ähnlicher Weise erheblich beeinträchtigt.“ Das bedeutet, dass bei jedem automatisierten Entscheidungssystem, das erhebliche Auswirkungen auf eine Person hat (z. B. Ablehnung eines Kreditantrags, eines Stellenangebots oder einer öffentlichen Leistung), ein Mensch in den Prozess einbezogen werden muss, um die Entscheidung zu überprüfen und zu validieren. Die Person hat auch das Recht, die automatisierte Entscheidung anzufechten und menschliches Eingreifen zu erwirken.

Und, nicht unerwartet, ist die menschliche Aufsicht eine zentrale Anforderung sowohl in der ISO 42001 als auch im NIST AI Risk Management Framework (AI RMF). Beide Rahmenwerke betonen, obwohl sie sich in ihrem Ansatz unterscheiden, die Notwendigkeit menschlichen Eingreifens, um den verantwortungsvollen und ethischen Einsatz von KI-Systemen zu gewährleisten.
Dieser Beitrag ist meine Interpretation des Papiers, das auf der letzten Sitzung des monatlichen Data61 AI Adoption and Assurance Chat vorgestellt wurde – „Designing meaningful human oversight in AI“ (https://www.researchgate.net/publication/395540553_Designing_Meaningful_Human_Oversight_in_AI).
(die vollständige Zitation für das Papier: Zhu, Liming & Lu, Qinghua & Ding, Ming & Lee, Sunny & Wang, Chen & Data, & Csiro, & Australia,. (2025). Designing Meaningful Human Oversight in AI. 10.13140/RG.2.2.16624.11528)
Das Papier diskutiert das Problem mit dem aktuellen Ansatz zur menschlichen Aufsicht und gibt praktische Tipps für Entwickler von KI-Systemen.
Was ist menschliche Aufsicht und wie wird sie durchgeführt?
Das Problem mit der menschlichen Aufsicht ist, dass sie schlecht definiert ist. Aber meiner Meinung nach wird alles durch unsere natürliche Automatisierungsverzerrung komplizierter – eine Tendenz, dem Ergebnis einer Maschine mehr zu vertrauen als unserem eigenen Urteil. Wie oft sind Sie blind einem GPS in eine nicht existierende Straße gefolgt?
Infolgedessen genehmigen wir entweder das Systemergebnis, ohne es richtig zu verstehen („Abstempeln“).
Zum Beispiel kann das KI-System einer Bank Ihre Transaktion als hochriskant einstufen, und ein menschlicher Analyst, der mit der Überprüfung von Tausenden solcher Warnungen täglich beauftragt ist, genehmigt automatisch die Entscheidung der KI und friert Ihr Konto ein.
Das gegenteilige Szenario ist ebenfalls üblich: Wir schränken das System so sehr ein, dass wir, anstatt ihm ein übergeordnetes Ziel und etwas Freiheit zum Ausloten von Kompromissen zu geben, versuchen, jede einzelne Aktion vorzuprogrammieren, die es ausführen soll, und es so auf ein regelbasiertes Automatisierungssystem reduzieren.
Ein Unternehmen möchte, dass ein KI-Chatbot Kundenanfragen bearbeitet. Anstatt ihm ein übergeordnetes Ziel wie „das Problem des Kunden höflich und effizient lösen“ zu geben, programmieren Sie ihn mit einem starren Skript, das vorschreibt, dass der Bot, wenn ein Kunde fragt: „Wie kann ich ein Produkt zurückgeben?“, mit einem Link zur Rückgabeseite antworten und dann fragen muss: „Hat diese Antwort Ihre Frage beantwortet?“ Er kann keine nuancierten Fragen wie „Ich habe meinen Beleg verloren, kann ich das trotzdem zurückgeben?“ beantworten, da die Regeln diesen speziellen Fall nicht abdecken. Der Chatbot verliert seine Handlungsfähigkeit und wird zu einem einfachen, frustrierenden Entscheidungsbaum.
Das Papier argumentiert, dass keines dieser Szenarien optimal ist und dass menschliche Handlungsfähigkeit und KI-Handlungsfähigkeit kein Nullsummenspiel sind. Die Zusammenarbeit der beiden führt zu besseren Ergebnissen, als jeder für sich allein erreichen könnte.
Wie kann menschliche Aufsicht gestaltet werden, um diese Zusammenarbeit zu ermöglichen?
Zwei Arten von Handlungsfähigkeit
Beginnen wir mit der Definition von Handlungsfähigkeit: Es ist die Fähigkeit, selbstständig zu handeln und Dinge zu bewirken, um ein Ziel zu erreichen.
Das Papier schlägt vor, zwischen zwei Arten von Handlungsfähigkeit zu unterscheiden:
- Operative Handlungsfähigkeit (die Fähigkeit der KI, Lösungen zu generieren)
Zum Beispiel generiert ein medizinisches KI-System eine Diagnose.
- Evaluative Handlungsfähigkeit (die Fähigkeit des Menschen, die Lösung der KI zu verstehen, zu beurteilen, zu überprüfen und gegebenenfalls ihre Ergebnisse zu steuern oder durch alternative Lösungen zu ersetzen)
Ein Arzt repliziert den Diagnoseprozess nicht. Es ist nicht die Aufgabe eines Arztes, die Arbeit der KI zu wiederholen oder die Maschine zu überlisten. Stattdessen besteht ihre Rolle darin, die Diagnose der KI zu bewerten. Der Arzt fragt: „Macht das Sinn? Ist die Argumentation der KI mit dem vereinbar, was ein verantwortungsbewusster menschlicher Experte tun würde?“ Sie prüfen auf Konsistenz. Sie überprüfen die Begründung der KI, die eine Liste der wichtigsten Symptome und ein Zitat aus der medizinischen Literatur sein könnte. Der Arzt überprüft, ob diese Argumentation mit seiner eigenen Ausbildung und den medizinischen Standards übereinstimmt. Sie fügen auch den menschlichen Kontext hinzu: Da sie wissen, dass die Behandlung einer seltenen Krankheit eine teure, schmerzhafte und intensive einjährige Therapie ist, berücksichtigen sie die Vorlieben des Patienten, seine finanzielle Situation und ob er bereit ist, sich einem so schwierigen Regime zu unterziehen. Schließlich wägen sie die potenziellen Vorteile der Behandlung gegen ihre erhebliche Belastung ab und entscheiden, ob dies der am besten geeignete und ethischste Weg ist, auch wenn die Diagnose der KI technisch korrekt ist.
Es ist schwer, der Meinung der Autoren zu widersprechen, dass „bewerten“ ein besseres Wort ist als „beaufsichtigen“, da es die menschliche Rolle als aktiv und urteilend hervorhebt, anstatt nur überwachend oder symbolisch.
Evaluative Handlungsfähigkeit schafft Verantwortlichkeit
Wenn etwas schief geht, ist letztendlich ein Mensch verantwortlich. Die KI kann nicht vor Gericht zur Rechenschaft gezogen werden; die Person, die ihr Ergebnis bewertet hat, schon. Außerdem verankert das Urteil des Menschen die Handlungen der KI in beruflichen, ethischen und gesellschaftlichen Standards, die die KI selbst nicht verstehen kann. Die KI kann den schnellsten Weg finden, aber nur der Mensch kann entscheiden, ob dieser Weg der ethischste oder sicherste ist. Diese beiden Vorteile sind der Schlüssel zu einer verantwortungsvollen und vertrauenswürdigen KI.
Interne vs. externe Argumentationstreue
Wie können wir die Ergebnisse eines Systems bewerten, wenn wir die komplexen internen Abläufe moderner KI-Modelle immer noch nicht vollständig erfassen können? Jede Aktivierung eines neuronalen Netzes, jede Parameteranpassung oder wie das erlernte Wissen des Modells (wie das Konzept einer „Katze“) in seinen Millionen oder Milliarden von Parametern (dem Gedächtnis des Modells) verteilt und gespeichert wird – der Versuch, diese algorithmische Schaltung zu verstehen, ist in diesem Stadium der KI-Entwicklung nicht machbar, und selbst wenn es so wäre, wäre es, als würde man die Entscheidungen eines Schachcomputerprogramms durch das Prisma einzelner Berechnungen betrachten, die es macht – zu viele Details, zu komplex und nicht sehr nützlich, um die Entscheidungen tatsächlich zu bewerten.
Stattdessen können wir Systeme so gestalten, dass sie Erklärungen liefern, die für einen Menschen Sinn ergeben – Erklärungen, die auf dem basieren, was das Papier als „externe Argumentationstreue“ oder „Plausibilität“ bezeichnet. Ein Schachprogramm würde sagen: „Ich habe diesen Zug gewählt, um das Zentrum des Bretts zu kontrollieren und Druck auf den Springer des Gegners auszuüben“, und wir wären in der Lage, diese Entscheidung zu bewerten, da ihre Erklärung mit etablierten Schachprinzipien und menschlichem Urteilsvermögen übereinstimmt.
Wie entwerfen wir nun ein System, das solche Hinweise liefert, die wir bewerten und bei Bedarf anfechten können?
Lösungs-Verifizierungs-Asymmetrie
Das Papier führt ein nützliches Konzept der Lösungs-Verifizierungs-Asymmetrie ein: Die Schwierigkeit, eine Lösung zu erstellen (Lösen), und die Schwierigkeit, diese Lösung zu überprüfen (Verifizieren), sind oft nicht gleich. Dies ist sowohl zur Entwurfszeit als auch zur Laufzeit der Fall, und das Verständnis dafür hilft, einen effektiven Prozess der menschlichen Aufsicht zu schaffen.
In der Entwurfsphase ist die „Lösungs“-Aufgabe der Aufwand, der für den Bau des KI-Systems erforderlich ist:
- Erstellen der Systemarchitektur
- Spezifizieren von Zielen
- Implementieren des Systems
- Entwerfen von Verifizierungsaufgaben und Schwellenwerten, die auf viele zukünftige Instanzen angewendet werden sollen
Die „Verifizierungs“-Aufgabe ist der Aufwand, dieses System zu bewerten und zu validieren, bevor es bereitgestellt wird:
- Überprüfung der Anforderungen
- Bewertung von Architektur und Design
- Testen
- andere Formen der Verifizierung und Validierung
Zur Laufzeit betrachten wir einzelne Instanzen – spezifische Ausgaben des Systems, spezifische Lösungen, die es vorschlägt. Die „Verifizierungs“-Aufgabe besteht hier darin, diese einzelnen Ausgaben zu bewerten. Manchmal sind die „Lösungs“-Aufgaben sehr rechenintensiv, aber die Überprüfung der Ausgaben ist einfach; es gibt jedoch Fälle, in denen die KI schnell eine Ausgabe generiert, aber der Mensch, der das System überwacht, viel Zeit und Mühe aufwenden wird, um sie zu überprüfen (z. B. Faktenprüfung, Überprüfung auf Voreingenommenheit, Sicherstellung der Übereinstimmung des Inhalts mit Standards usw.), und die Überprüfung wird zum Engpass.
Die wichtigste Erkenntnis ist, dass eine effektive Aufsicht sich an diese Asymmetrie anpassen muss.
Wenn die Überprüfung zur Entwurfszeit einfach ist
Bei dieser Strategie geht es darum, Sicherheit von Anfang an einzubauen. Indem Sie den Überprüfungsprozess vorverlagern, können Sie potenzielle Probleme erkennen, bevor die KI überhaupt eingesetzt wird, und so den Bedarf an ständiger, manueller Überwachung reduzieren.
Zum Beispiel muss der Arm eines Fabrikroboters mit hoher Präzision und Sicherheit arbeiten und immer in seinem vorgesehenen Arbeitsbereich bleiben. Die Überprüfung, dass er einen in der Nähe befindlichen menschlichen Arbeiter nicht verletzen wird, erfolgt während der Entwurfs- und Programmierphase durch umfangreiche Tests, Modellierung und vorprogrammierte Sicherheitsparameter. Das Ziel ist es, sicherzustellen, dass das System „sicher durch Design“ ist, was ein menschliches Eingreifen in Echtzeit in seine grundlegenden Bewegungen unnötig macht.
Wenn die Überprüfung zur Entwurfszeit schwierig ist
Dieses Papier erkennt an, dass einige KI-Aufgaben zu komplex sind, um während der Entwicklung vollständig überprüft zu werden. In diesen Fällen kann das System so konzipiert werden, dass es einem menschlichen Bediener klare, umsetzbare Informationen liefert, der dann eine fundierte endgültige Entscheidung treffen kann. Der Mensch fungiert als letzte Kontrollinstanz.
Zum Beispiel führt ein KI-System, das eine Diagnose empfiehlt, eine hochkomplexe Aufgabe aus. Seine Genauigkeit kann während der Entwicklung schwer vollständig zu überprüfen sein, da es unendlich viele Variationen in der menschlichen Anatomie und bei Krankheiten gibt. Daher sollte das System so konzipiert sein, dass es eine Laufzeitüberprüfung erleichtert: Es gibt nicht nur eine Diagnose, sondern auch einen Konfidenzwert (z. B. „95 % Wahrscheinlichkeit eines gutartigen Tumors“), hebt die spezifischen Bereiche eines Scans hervor, die zu seiner Schlussfolgerung geführt haben, fügt andere relevante Zitate hinzu und bietet eine detaillierte Erklärung seiner Argumentation (Argumentationsspuren). Ein Arzt kann diese Informationen dann nutzen, um die endgültige, fundierte Diagnose zu stellen.
Was ist mit subjektiven Bereichen, in denen es keine richtige Antwort gibt?
In Bereichen wie Kunst, Ethik oder strategischer Planung haben verschiedene Menschen unterschiedliche Werte und Perspektiven. Anstatt ein KI-System zu haben, das die ganze Vielfalt in eine einzige „richtige“ Antwort „kollabieren“ lässt, wo es oft keine gibt, sollten wir die KI als Partner in einer Diskussion gestalten. Das Ziel ist nicht, eine perfekte Lösung zu erhalten, sondern verschiedene Perspektiven und Szenarien aufzuzeigen. Dieser Ansatz macht Meinungsverschiedenheiten zu einem wertvollen Teil des Prozesses, da die KI Ihnen die verschiedenen Kompromisse und Standpunkte zeigen kann. Dadurch wird das System rechenschaftspflichtiger, da es Sie, den Menschen, zwingt, diese Optionen aktiv zu berücksichtigen und eine durchdachte, gut begründete Entscheidung auf der Grundlage aller verfügbaren Blickwinkel zu treffen.
Grenze der Delegation
Die Autoren des Papiers betonen, dass es eine Grenze gibt, jenseits derer die KI nicht mehr der primäre Entscheidungsträger sein sollte – sie nennen es „Grenze der Delegation“. In bestimmten hochriskanten Bereichen wie der Strafzumessung, der medizinischen Diagnose oder der Einstellung von Personal hat das endgültige Urteil ein erhebliches ethisches und normatives Gewicht. Diese Entscheidungen sollten nicht vollständig an die KI delegiert werden. In diesen Fällen geht es bei der Aufsicht nicht nur darum, zu prüfen, ob das Ergebnis der KI korrekt ist. Es geht darum, die menschliche Verantwortung zu wahren. Die KI sollte als Werkzeug zur Unterstützung des menschlichen Entscheidungsträgers fungieren, Daten und Erkenntnisse liefern, aber niemals seine Rolle vollständig ersetzen. Die endgültige Entscheidung muss bei einem Menschen bleiben, um ethische und moralische Rechenschaftspflicht zu gewährleisten.
3 Cs für eine effiziente menschliche Aufsicht
Was müssen wir erreichen, wenn wir den KI-Aufsichtsprozess gestalten?
- Kontrolle (wir Menschen können rechtzeitig und wirksam eingreifen, um eine Entscheidung der KI anzuhalten, umzuleiten oder zu ersetzen)
- Anfechtbarkeit (KI-Entscheidungen werden durch verständliche Gründe und Beweise gestützt, sodass sie überprüft und angefochten werden können)
- Kompetenz (Aufsicht verbessert die Gesamtleistung und Fairness des Systems und vermeidet pauschale Übersteuerungen, die die korrekten Ergebnisse der KI beeinträchtigen würden)
Bedingungen für Handlungsfähigkeit und Aufsicht
Das Papier bezieht sich auf die Bedingungen für Handlungsfähigkeit (Individualität, Handlungsquelle, Zielgerichtetheit und Anpassungsfähigkeit) als Rahmen für die Gestaltung einer effektiven menschlichen Aufsicht sowohl zur Entwurfszeit als auch zur Laufzeit. Sie können mehr über diese Bedingungen in einem anderen Papier lesen – Agency is Frame-Dependent
Schauen wir uns jede dieser Bedingungen an – und die praktischen Tipps zur Gestaltung der menschlichen Aufsicht, die das Papier den Systementwicklern für jede von ihnen anbietet.
Individualität
Diese Bedingung erfordert eine klare Grenze zwischen der Rolle der KI (operative Handlungsfähigkeit) und der Rolle des Menschen (evaluative Handlungsfähigkeit). Hier müssen wir den Entwurf für die Mensch-KI-Interaktion erstellen, bei dem die KI frei sein sollte, autonom zu arbeiten, und der Mensch nur an bestimmten, genau definierten Kontrollpunkten eingreifen sollte. Das Verwischen dieser Grenzen führt zu einer Verwässerung der Rechenschaftspflicht.
Entwurfszeit
- Definieren Sie die Grenzen des Systems und legen Sie explizite Übergabepunkte für menschliches Eingreifen fest.
Wo endet die Aufgabe der KI? Nicht nur „Das System wird den Kundenservice übernehmen“, sondern „Das System wird Kundenfragen zu Produktspezifikationen aus einer vordefinierten Wissensdatenbank beantworten. Es wird keine Abrechnungsstreitigkeiten oder Rückerstattungen bearbeiten.“
- Fügen Sie Bedingungen für die Enthaltung (die Weigerung, eine Anfrage zu beantworten) hinzu, wenn das System einen Fall zur menschlichen Intervention kennzeichnen muss, anstatt zu raten.
Zum Beispiel, wenn der Konfidenzwert < 90 % ist, signalisiert das System einem Menschen, dass es in einem „Graubereich“ operiert.
- Definieren Sie vorbestimmte menschliche Übergabepunkte – wo die Kontrolle von der KI auf einen Menschen übergeht.
Es geht nicht nur um einen niedrigen Konfidenzwert, sondern um die Bedeutung der Aktion selbst. Zum Beispiel, selbst wenn eine KI zu 99 % zuversichtlich ist, wenn die Entscheidung eine Finanztransaktion über 1 Million US-Dollar oder eine kritische medizinische Diagnose betrifft, macht die hochriskante Natur der Aufgabe sie zu einem obligatorischen menschlichen Kontrollpunkt. Hier ist ein Beispiel, wie die menschliche Übergabe in MS Copilot-Agenten implementiert werden kann:
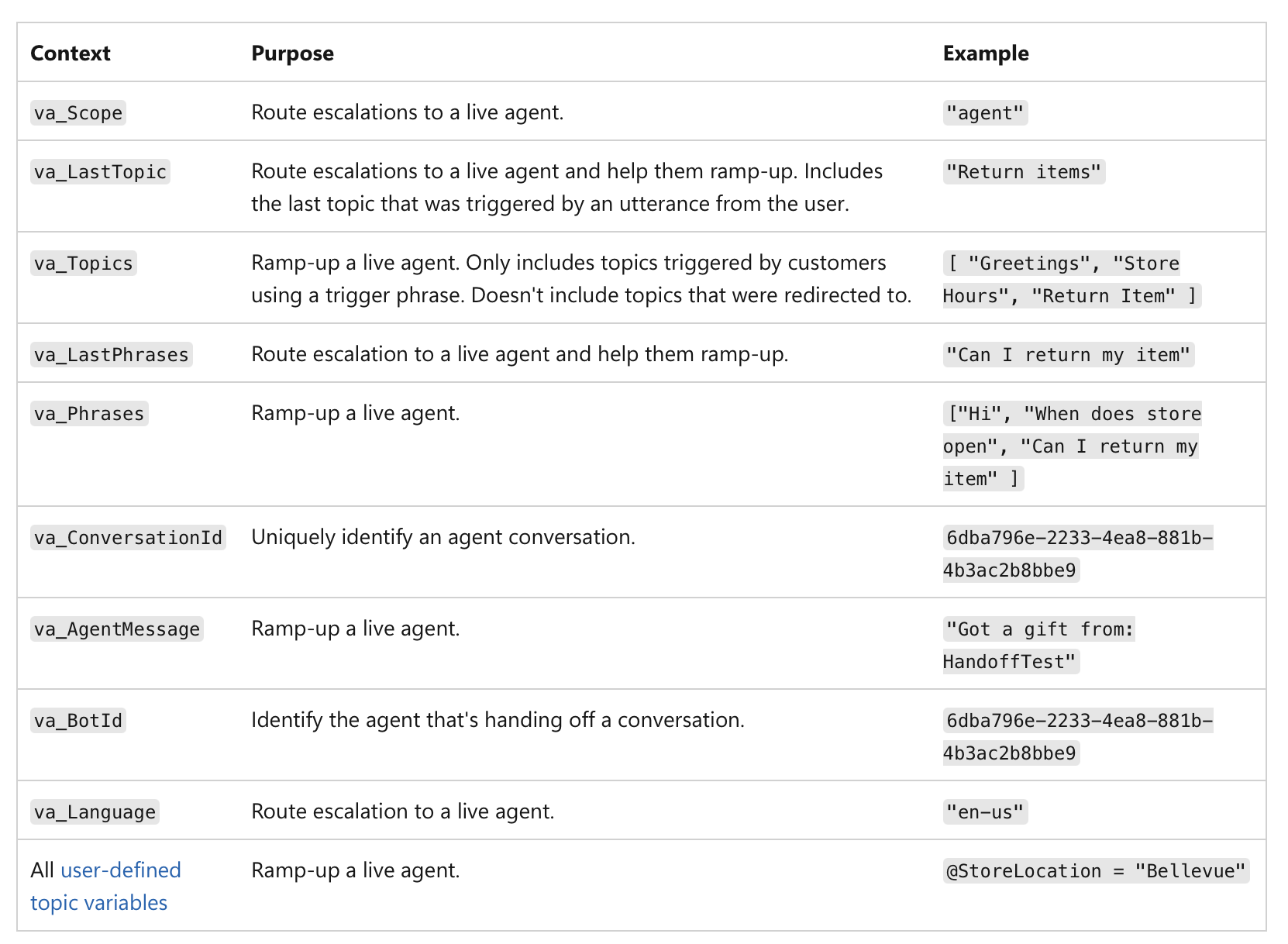 (Quelle)
(Quelle)
Laufzeit
Sobald das System live ist, verlagert sich der Fokus auf Protokollierung und Rechenschaftspflicht.
- Protokollieren Sie, wann die Kontrolle tatsächlich von der KI auf den Menschen übergeht.
Ihr System muss eine unveränderliche Aufzeichnung (z. B. auf einer Blockchain oder einer einmal beschreibbaren Datenbank – um Manipulationen zu verhindern) jeder Übergabe erstellen: Das Protokoll sollte einen Zeitstempel, die letzte Aktion der KI und die Identität des Menschen enthalten, der die Kontrolle übernommen hat:
„Kreditantrag Nr. 12345 um 10:30 Uhr an den menschlichen Analysten Mary Smith übergeben, da der Kredit-Score unter dem Schwellenwert liegt.“
Dies gewährleistet eine klare Rechenschaftspflicht für die endgültige Entscheidung.
Die protokollierten Daten können zur Erstellung von Dashboards und Berichten für die Aufsicht verwendet werden – Sie können sehen, wie oft menschliches Eingreifen erfolgt, ob die Empfehlungen der KI angenommen oder abgelehnt werden und wer die endgültigen Entscheidungen trifft. Dies hilft uns, Bereiche zu identifizieren, in denen die Leistung der KI schwach sein könnte oder in denen menschliche Prozesse verfeinert werden müssen.
Handlungsquelle
Hier verfolgen wir die Ursache einer Ausgabe. Der generative Prozess einer KI ist oft undurchsichtig, daher kann der Versuch, ihn durch sorgfältiges Erstellen von Prompts „mitzubestimmen“, nur eine Illusion der Kontrolle sein. Stattdessen sollte sich die menschliche Aufsicht auf die Bewertung der endgültigen Ausgabe konzentrieren, indem sie die kausale Historie (Prompts, Eingaben, KI-Aufrufe) (auch bekannt als Provenienz) überprüft.
Entwurfszeit
-
Stellen Sie sicher, dass das System eine vollständige Aufzeichnung seiner Herkunft durch eine durchgängige Protokollierung (unveränderlich und für die maschinelle Lesbarkeit standardisiert) erfassen kann, bei der jeder Schritt im Arbeitsablauf der KI automatisch protokolliert und mit einem Zeitstempel versehen wird:
- verwendete Eingabedaten und Prompts
- spezifische Version des KI-Modells, das zur Generierung der Ausgabe verwendet wurde
- vollständige Historie menschlicher Anweisungen und Änderungen
- alle externen Aufrufe, externen Dienste, APIs, Datenbanken, auf die das KI-System zugegriffen hat
- Zwischenergebnisse, die das System generiert, aber letztendlich verworfen hat
Dieser Vorabdruck von „Using Blockchain Ledgers to Record the AI Decisions in IoT“ diskutiert zum Beispiel, wie dies in der Praxis umgesetzt werden kann: https://www.preprints.org/manuscript/202504.1789/v1 Hier ist ein Beispiel aus diesem Vorabdruck:
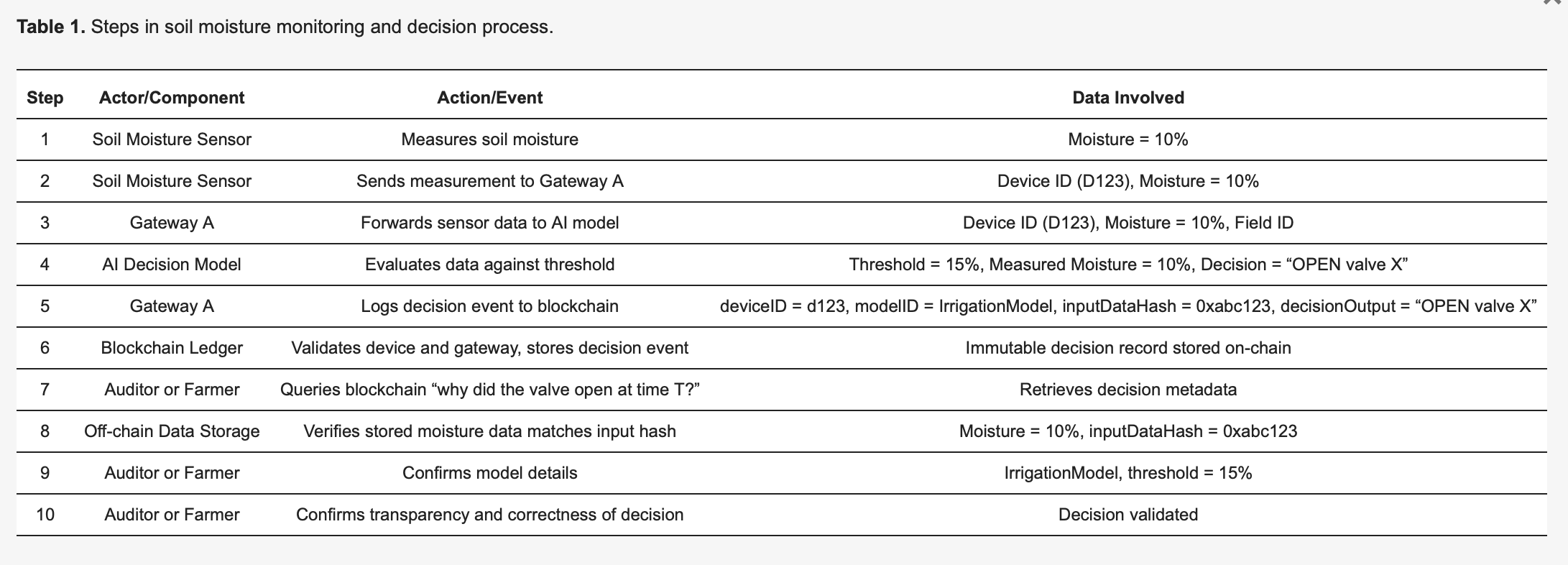
Um die Methodik konkret zu machen, betrachten Sie ein IoT-basiertes intelligentes Bewässerungssystem [27], das in Tabelle 1 detailliert beschrieben ist. Bodenfeuchtigkeitssensoren (Geräte) senden Messwerte an ein Edge-KI-Modell, das entscheidet, ob Wasserventile geöffnet oder geschlossen bleiben sollen. Jede von der KI getroffene Entscheidung löst ein Protokollierungsereignis aus, das unveränderlich in einem Blockchain-Ledger erfasst wird, was die Transparenz und Überprüfbarkeit verbessert. Wie in Tabelle 1 dargestellt, erfasst Sensor 123 eine Feuchtigkeit von 10 Prozent und überträgt diese Messung an Gateway A. Gateway A leitet die Daten an das KI-Modell weiter, das aufgrund eines vordefinierten Schwellenwerts von 15 Prozent (spezifiziert durch IrrigationModelv2) die entsprechende Aktion bestimmt: „Ventil = OFFEN“ für Feld X. Gateway A bereitet dann eine Transaktion vor, die kritische Metadaten enthält – einschließlich der deviceID (123), modelID (IrrigationModelv2), eines Hashs der Eingabedaten (0xabc123) und des Entscheidungsergebnisses (Ventil X ÖFFNEN) – signiert sie und übermittelt sie an die Blockchain. Blockchain-Knoten überprüfen die Authentizität und Berechtigungen von Sensor 123 und Gateway A, bestätigen, dass sie ordnungsgemäß für Feld X registriert sind, und speichern den Datensatz anschließend dauerhaft. Ein Ereignis wird ausgegeben, um eine erfolgreiche Protokollierung anzuzeigen. Später kann ein Prüfer oder der Landwirt abfragen, „warum wurde zum Zeitpunkt T Wasser freigesetzt?“, und den detaillierten Transaktionsdatensatz aus der Blockchain abrufen. Der Hash (0xabc123) aus der Blockchain kann dann mit extern gespeicherten Sensordaten (gespeichert auf IPFS oder der Datenbank von Gateway A) abgeglichen werden, um zu bestätigen, dass der Feuchtigkeitsmesswert tatsächlich 10 Prozent betrug. Darüber hinaus kann der Landwirt unter Bezugnahme auf das Modellregister validieren, dass der Bewässerungsschwellenwert auf 15 Prozent Feuchtigkeit eingestellt war, was bestätigt, dass die Entscheidung der KI korrekt und gerechtfertigt war. Dieser strukturierte Prozess verbessert die Transparenz erheblich: Jede automatisierte Aktion ist überprüfbar und durch protokollierte Metadaten vollständig erklärbar, und die Unveränderlichkeit der Blockchain stellt sicher, dass weder Farmbetreiber noch Gerätehersteller heimlich Entscheidungsprotokolle ändern können.
Laufzeit
- Überprüfen Sie die kausale Kette für den spezifischen Fall, um zu sehen, wie die Ausgabe generiert wurde.
- Verwenden Sie ein visuelles Dashboard, das die gesamte kausale Kette für eine bestimmte Ausgabe abbildet, um das Endergebnis und jeden Schritt, der dazu geführt hat, zu sehen.
Wenn Sie eine Entscheidung überprüfen möchten, können Sie den Herkunftsdatensatz für diesen speziellen Fall aufrufen. Sie müssen nicht den internen „generativen Pfad“ der KI verstehen (die komplexe Mathematik und die neuronalen Aktivierungen). Stattdessen überprüfen Sie die Herkunftsmetadaten, um Fragen wie diese zu beantworten:
„Wurden die richtigen Daten verwendet?“
Wenn ein Arzt beispielsweise den Herkunftsdatensatz aufruft, zeigen die Metadaten eine Liste der spezifischen Datenpunkte, die die KI verwendet hat. Der Herkunftsdatensatz bestätigt, dass die KI die vollständige Krankengeschichte des Patienten, einen aktuellen Bluttest vom 24.10.25 und einen MRT-Scan vom 26.10.25 verwendet hat und alle Datenpunkte mit der offiziellen elektronischen Gesundheitsakte übereinstimmen. In einem anderen Fall kann der Arzt zu dem Schluss kommen, dass der Herkunftsdatensatz zeigt, dass die KI auf Bluttestdaten von vor zwei Jahren zugegriffen hat, aber die Patientenakte letzte Woche mit neuen Ergebnissen aktualisiert wurde und die KI veraltete Informationen verwendet hat.
„Wurde die Aufforderung des Menschen korrekt verarbeitet?“
Die Aufforderung des Arztes an die KI lautete: „Symptome analysieren und eine Diagnose für einen 45-jährigen Mann mit anhaltendem Husten und Fieber empfehlen.“ Der Herkunftsdatensatz protokolliert die genaue Anfrage, die die KI erhalten hat. Der Arzt vergleicht dies mit seiner ursprünglichen Eingabe und stellt fest, dass die protokollierte Anfrage zeigt, dass die Aufforderung abgeschnitten wurde und das Symptom „Fieber“ fehlt – die KI hat also nur „anhaltenden Husten“ verarbeitet, was zu einem anderen diagnostischen Pfad führte.
„Wurde die richtige Modellversion bereitgestellt?“
Der Herkunftsdatensatz kann zeigen, dass die Diagnose von einer älteren Version des Modells generiert wurde, die aufgrund eines Systemfehlers hätte außer Betrieb genommen werden sollen.
Hier ordnet das System Aktionen eindeutig entweder der autonomen Generierung der KI oder einem spezifischen menschlichen Eingriff zu. Dies ermöglicht eine klare Rechenschaftspflicht. Wenn eine schlechte Entscheidung getroffen wird, kann eine schnelle Überprüfung des Herkunftsprotokolls aufdecken, ob es sich um eine fehlerhafte KI-Ausgabe oder einen menschlichen Bewertungsfehler handelte, und so das „Schuldzuweisungsspiel“ verhindern, bei dem die Handlungsfähigkeit diffus wird.
Zielgerichtetheit
Die KI sollte untergeordnete Ziele auf niedriger Ebene handhaben, während Menschen die Autorität über übergeordnete Ziele behalten. Die Rolle des Menschen besteht darin, sicherzustellen, dass der von der KI gewählte Weg mit umfassenderen Zielen und Einschränkungen wie gesetzlichen Anforderungen oder Fairnesszielen übereinstimmt.
Entwurfszeit
- Veröffentlichen Sie explizit die übergeordneten Ziele, Einschränkungen und Kompromissregeln für die KI.
Die von Menschen definierten übergeordneten Ziele werden klar und zugänglich gemacht. Dies sind nicht nur vage Leitbilder; es sind greifbare, oft numerische Ziele. Für eine Logistik-KI könnte dies sein: „Lieferzeit um 15 % reduzieren, ohne die Kraftstoffkosten zu erhöhen.“ Für eine Einstellungs-KI könnte ein übergeordnetes Ziel lauten: „qualifizierte Bewerbungen um 20 % steigern und gleichzeitig sicherstellen, dass bei der Kandidatensuche keine rassistische oder geschlechtsspezifische Voreingenommenheit besteht.“
- Definieren Sie Einschränkungen und Kompromissregeln.
Menschliche Autorität wird durch Grenzen und Regeln ausgedrückt. Der KI sollten explizite Grenzen gesetzt werden, die sie nicht verletzen darf. Zum Beispiel „innerhalb des gesetzlichen Budgets bleiben“, „keine Handlung empfehlen, die gegen Datenschutzgesetze verstößt“ oder „Fairness über reine Effizienz stellen“. In Fällen, in denen Ziele in Konflikt stehen (z. B. Geschwindigkeit vs. Kosten), müssen die von Menschen definierten Kompromissregeln vorschreiben, welches Vorrang hat.
Laufzeit
Hier verlagert sich der Fokus auf Überwachung und Bewertung. Ein Mensch muss nicht jeden einzelnen Rechenschritt kennen, aber er kann sehen, ob die allgemeine Richtung der KI mit dem übergeordneten Ziel übereinstimmt. Wir können den Fortschritt an bestimmten vordefinierten Punkten bewerten.
- Testen Sie, ob die aktuelle Ausgabe und die untergeordneten Ziele der KI mit den deklarierten Zielen übereinstimmen.
Zum Beispiel könnte einer Finanz-KI erlaubt sein, mehrere Simulationen zur Optimierung eines Portfolios durchzuführen (untergeordnete Ziele), aber ein menschlicher Analyst muss die endgültige Strategie genehmigen, um sicherzustellen, dass sie mit der Risikotoleranz des Kunden und den gesetzlichen Anforderungen übereinstimmt (übergeordnete Ziele). Dieser Prozess ermöglicht es der KI, ihre „operative Handlungsfähigkeit“ zur Erkundung von Lösungen zu nutzen, während der Mensch die „evaluative Handlungsfähigkeit“ behält, um sicherzustellen, dass die Richtung der KI legitim bleibt.
- Stellen Sie sicher, dass das System so konzipiert ist, dass es seinen Fortschritt bei der Erreichung seiner untergeordneten Ziele kontinuierlich überwacht und darüber berichtet.
Für eine KI zur Inhaltserstellung könnte dies bedeuten, dass sie über ihre Versuche berichtet, bestimmte Schlüsselwörter zu finden, oder über ihre Strategie zur Strukturierung des Artikels.
- Das System sollte eine klare, nachvollziehbare Aufzeichnung seiner Entscheidungen erstellen, einschließlich der Gründe, warum es ein bestimmtes untergeordnetes Ziel verfolgt hat. Diese Aufzeichnung wird einem menschlichen Bewerter zur Verfügung gestellt.
Wenn eine KI ein voreingenommenes Ergebnis generiert, kann ein Prüfer ihren Weg zurückverfolgen und sehen, wo sie von den in der Entwurfsphase definierten Fairness-Einschränkungen abzuweichen begann.
Anpassungsfähigkeit
Ein Mensch kann nicht jede geringfügige interne Änderung, die eine KI vornimmt, vernünftigerweise überwachen. Die menschliche Aufsicht sollte auf wesentliche Änderungen abzielen, wie z. B. Änderungen der Richtlinien oder des allgemeinen Systemverhaltens. Es geht darum, die Leitplanken für das adaptive Verhalten der KI zu schaffen.
Entwurfszeit
- Richten Sie Änderungskontrollen und Drift-Monitore ein, die signifikante Verhaltensänderungen erkennen.
Das System sollte so konzipiert sein, dass es seine eigenen Modelle und Konfigurationen versioniert, um bei Problemen auf eine frühere, stabile Version zurückgreifen zu können.
Drift-Monitore sind Werkzeuge, die die Leistung und das Verhalten der KI in der realen Welt ständig verfolgen. Sie messen nicht nur die Genauigkeit; sie suchen nach Konzeptdrift (wenn sich die Beziehung zwischen Eingabe- und Ausgabedaten ändert) und Datendrift (wenn sich die Eingabedaten selbst ändern). Die Monitore werden mit spezifischen Schwellenwerten eingestellt. Zum Beispiel könnte der Drift-Monitor einer KI zur Betrugserkennung so eingestellt sein, dass er einen Menschen alarmiert, wenn seine Falsch-Positiv-Rate um mehr als 5 % steigt.
Laufzeit
Sobald das System live ist, beobachten es die Menschen nicht ständig. Sie werden von den automatisierten Monitoren alarmiert, sodass sie ihre Aufmerksamkeit effektiv konzentrieren können. Wenn der Schwellenwert eines Drift-Monitors überschritten wird, sendet er automatisch eine Warnung an ein menschliches Team. Die Warnung sollte eine Momentaufnahme des beobachteten Verhaltens und der relevanten Daten enthalten, damit der Mensch die Situation schnell beurteilen kann. Das System kann auch so vorprogrammiert werden, dass es bei Erkennung einer Änderung einem bestimmten Protokoll folgt.
Was bekomme ich, wenn ich dieses Framework implementiere?
Dieser Ansatz schafft eine starke Partnerschaft, in der das KI-System und der „beaufsichtigende“ Mensch jeweils eine eigene, wertvolle Rolle haben. Die KI kann ihre Rechenleistung frei nutzen, um komplexe Probleme anzugehen (ihre „operative Handlungsfähigkeit“), während der Mensch, der klare Signale vom System erhält, befähigt wird, fundierte, übergeordnete Entscheidungen zu treffen und bei Bedarf einzugreifen (seine „evaluative Handlungsfähigkeit“). Das Ergebnis ist eine „Nicht-Nullsummen“-Zusammenarbeit, bei der die kombinierte Anstrengung zu besseren Ergebnissen führt, als sie der Mensch oder die KI allein erreichen könnten.
Wie geht dieses Framework auf Art. 134 des KI-Gesetzes ein?
Das Framework geht direkt auf die Anforderungen des EU-KI-Gesetzes ein, insbesondere auf Artikel 134, indem es einen praktischen, umsetzbaren Ansatz für eine „wirksame menschliche Aufsicht“ bietet, der über abstrakte Prinzipien hinausgeht. Es definiert Aufsicht nicht als vage Verpflichtung, sondern als systematischen Prozess der Gestaltung von KI zur Unterstützung der menschlichen evaluativen Handlungsfähigkeit.
Was verlangt das KI-Gesetz von Entwicklern von KI-Systemen?
- „Geeignete Mensch-Maschine-Schnittstellenwerkzeuge … können wirksam überwacht werden.“
Das Kernprinzip des Frameworks ist, dass das KI-System selbst so gebaut sein muss, dass es eine Aufsicht ermöglicht. Das vom Papier vorgeschlagene Framework bietet grundlegende Designmerkmale, die sicherstellen, dass der Betrieb des Systems für einen Menschen transparent und handhabbar ist.
- „Zielen darauf ab, die Risiken zu verhindern oder zu minimieren.“
Der Schwerpunkt des Frameworks auf der evaluativen Handlungsfähigkeit geht direkt darauf ein. Die Rolle des Menschen besteht darin, das „übergeordnete Urteil“ zu liefern, das die Handlungen der KI an beruflichen und gesellschaftlichen Standards verankert. Dies ist der Mechanismus zur Verhinderung von Risiken, die die KI, die mit ihrer operativen Handlungsfähigkeit arbeitet, möglicherweise nicht erkennt. Die Entwurfszeitprüfungen des Frameworks (z. B. Festlegung von Fairnesszielen, Identifizierung von Hochrisikoentscheidungen) stellen sicher, dass die Risikoprävention ein beabsichtigter Teil der Systemarchitektur ist und nicht nachträglich erfolgt.
- „Maßnahmen … in das Hochrisiko-KI-System eingebaut.“
Die gesamte Struktur des Frameworks ist um diese Anforderung herum aufgebaut. Die „offenzulegenden KI-Artefakte“ und die „Systemverifizierungsoberfläche“ für jede Bedingung sind Beispiele für Maßnahmen, die vom Anbieter „in das Hochrisiko-KI-System eingebaut“ werden.
Die Individualitätsbedingung erfordert, dass das System mit klaren Übergabe-API-Verträgen entworfen wird. Die Anpassungsfähigkeitsbedingung erfordert eingebaute Drift-Monitore und Rollback-Mechanismen. Dies sind alles konkrete Maßnahmen, die vom Anbieter umgesetzt werden.
Das Framework leitet den Anbieter auch bei der Identifizierung von Maßnahmen für den Bereitsteller an. Zum Beispiel erfordert die Bedingung Handlungsquelle, dass der Anbieter dem Bereitsteller ein Herkunfts-Dashboard zur Verfügung stellt, was eine wichtige Maßnahme für den Bereitsteller ist, um sie zu implementieren und zu verwenden.
- „Menschliche Aufsicht … ermöglicht, soweit angemessen und verhältnismäßig.“ Das Framework übersetzt jeden Punkt dieses Unterartikels direkt in eine Designanforderung.
a) „Die relevanten Kapazitäten und Grenzen richtig verstehen“
Die Bedingungen Individualität und Zielgerichtetheit gehen darauf ein, indem sie eine explizite Dokumentation der Grenzen, Ziele und Einschränkungen der KI erfordern. Dies verschafft dem Menschen ein klares Verständnis der Fähigkeiten der KI.
b) „Sich der … Automatisierungsverzerrung bewusst bleiben“
Das Framework fördert die evaluative Handlungsfähigkeit als Gegengewicht zur Automatisierungsverzerrung. Die Betonung der Überprüfung der KI-Ergebnisse anstatt sie nur zu akzeptieren, zwingt den Menschen, engagiert zu bleiben, und bietet einen Mechanismus, um die KI bei Bedarf zu übersteuern.
c) „Die … Ausgabe korrekt interpretieren“
Die Bedingung Handlungsquelle stellt sicher, dass die Ausgabe der KI von interpretierbaren Metadaten und Herkunftsdatensätzen begleitet wird. Dies ermöglicht es dem Menschen, den Kontext und die kausale Kette der Ausgabe korrekt zu interpretieren, was eine einfache Urteilsfindung ermöglicht.
d) „Entscheiden … nicht zu verwenden … oder die Ausgabe zu missachten“
Die Bedingung Individualität unterstützt dies direkt, indem sie explizite Übergabepunkte und Mechanismen zum „Antwort verweigern und an einen Menschen übergeben“ erfordert, die den Menschen befähigen, einzugreifen und das System zu übersteuern.
e) „Eingreifen … oder unterbrechen … durch einen ‚Stopp‘-Knopf“
Die Rollback- und Enthaltungsmechanismen der Anpassungsfähigkeitsbedingung bieten das funktionale Äquivalent eines „Stopp“-Knopfes. Sie ermöglichen es einem Menschen, den Betrieb der KI auf sichere und kontrollierte Weise anzuhalten oder rückgängig zu machen.
f) „Überprüfung durch mindestens zwei natürliche Personen.“
Das Framework bietet die Werkzeuge, um dies zu einem machbaren und sinnvollen Prozess zu machen. Der Herkunftsdatensatz der Bedingung Handlungsquelle und ein klares Protokoll aller menschlichen Interaktionen machen es für zwei oder mehr Personen einfach, die Identifizierung einer KI unabhängig zu überprüfen. Sie können beide denselben Satz protokollierter Daten abrufen und die kausale Kette überprüfen, um einen Konsens zu erzielen, und so sicherstellen, dass die Überprüfung auf objektiven Beweisen und nicht auf subjektiven Vermutungen beruht.
Herausforderungen
Natürlich, obwohl das Framework sehr vielversprechend und anwendbar aussieht, ignoriert das Papier nicht die üblichen Nachteile der Implementierung der Aufsichtsmechanismen.
Komplexität und Kosten
Erstens sind nicht alle einfach einzurichten – viele erfordern einen erheblichen Aufwand im Voraus für Design und Bau. Sie benötigen spezialisiertes Fachwissen, um Systeme zu erstellen, die strukturierte Begründungen generieren, die Herkunft erfassen oder nuancierte Regeln in ein Ziel-Ledger kodieren können. Bereiten Sie sich außerdem auf laufende Kosten für die Wartung des Systems, die Kalibrierung von Signalen und die Schulung menschlicher Prüfer in den neuen Prozessen vor.
Signalabhängigkeit
Die Wirksamkeit dieser Aufsichtsmechanismen hängt stark von der Qualität der von ihnen erzeugten Signale ab. Wenn die KI schlechte oder verrauschte Signale erzeugt (z. B. ungenaue Konfidenzwerte, vage Begründungen oder fehlerhafte Herkunftsdaten), kann dies den menschlichen Prüfer irreführen und den gesamten Aufsichtsprozess untergraben.
Verifizierungsaufwand
Obwohl das Ziel darin besteht, die Effizienz zu verbessern, eliminieren diese Systeme den menschlichen Arbeitsaufwand nicht vollständig. In Grenzfällen, neuartigen oder mehrdeutigen Fällen muss der menschliche Prüfer möglicherweise immer noch intensive, manuelle Stichproben durchführen. Das Papier stellt fest, dass dies die Effizienzgewinne verringern kann, da die Prüfer möglicherweise viel Zeit damit verbringen müssen, Enthaltungen aufzulösen oder die Vorschläge der KI anzufechten. Die menschliche Belastung verlagert sich von einer umfassenden Bewertung zu einer detaillierten Überprüfung der Arbeit der KI, die immer noch erheblich sein kann.
Denken Sie daran: Ein Umdenken ist erforderlich
Es reicht also nicht aus, nur zu sagen, wir brauchen „menschliche Aufsicht“. Um dies zu verwirklichen, müssen wir unsere Denkweise von der einfachen „Überwachung der KI“ auf die Gestaltung der KI für die Zusammenarbeit zwischen KI und Mensch umstellen: die Rolle des Menschen als aktiver Bewerter neu definieren, die Aufsicht in das KI-Design integrieren, sich an die drei Cs erinnern – Kontrolle, Anfechtbarkeit und Kompetenz – und dann werden Sie nicht nur Vorschriften wie das KI-Gesetz einhalten – Sie werden ein vertrauenswürdigeres und leistungsfähigeres System schaffen, das mit Menschen zusammenarbeitet.
