AI human oversight
Human oversight in AI systems is a compliance requirement:
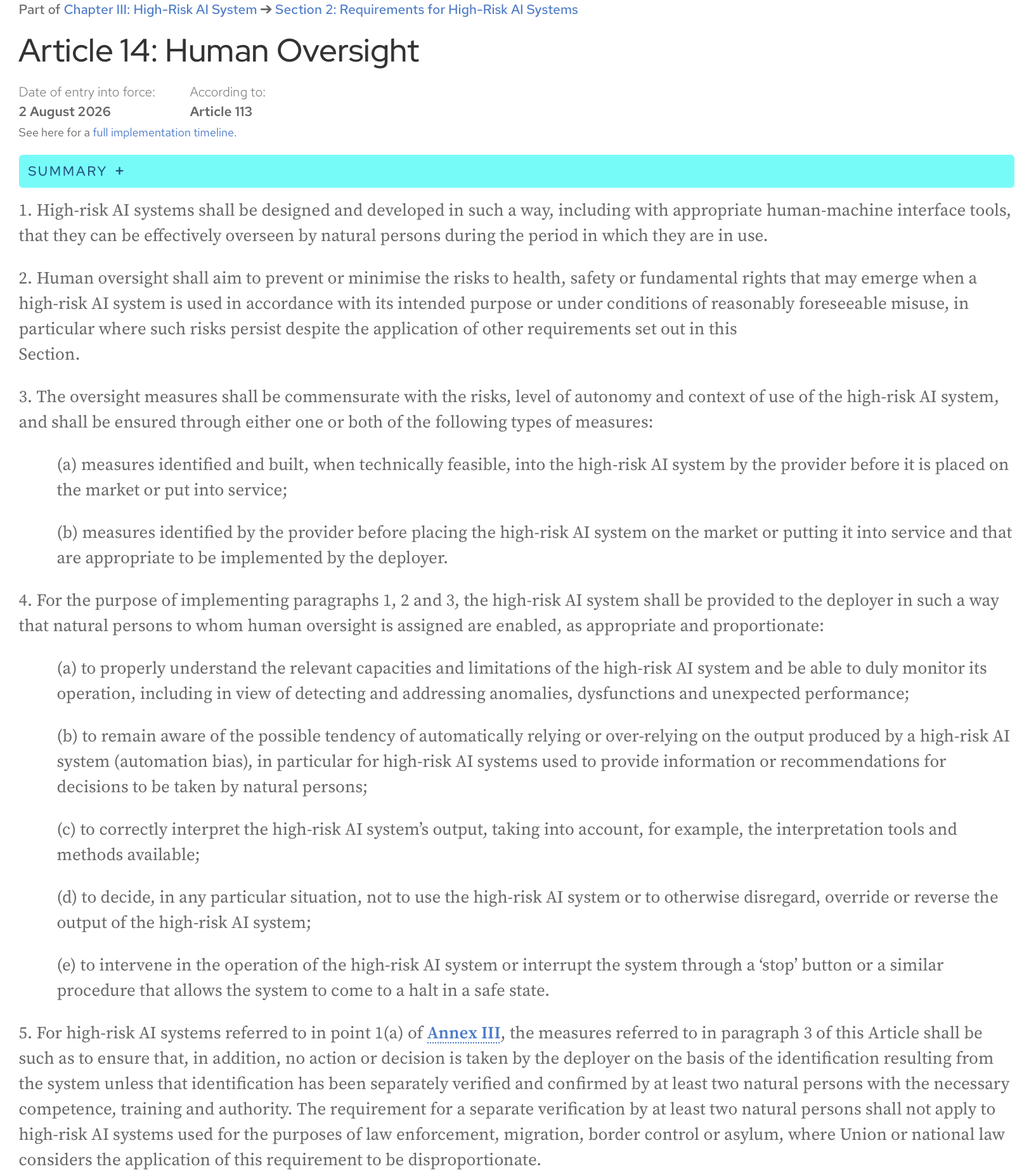
AI Act, Article 14: High-risk AI systems shall be designed and developed in such a way, including with appropriate human-machine interface tools, that they can be effectively overseen by natural persons during the period in which they are in use.
Here is the full text from the article from the official AI Act webpage:
Article 22 of the GDPR explicitly provides individuals with the right “not to be subject to a decision based solely on automated processing, including profiling, which produces legal effects concerning him or her or similarly significantly affects him or her.” This means that for any automated decision-making system that has a major impact on an individual (e.g., denying a loan application, a job offer, or a public benefit), a human must be involved in the process to review and validate the decision. The individual also has the right to contest the automated decision and obtain human intervention.

And, not unexpectedly, human oversight is a key requirement in both the ISO 42001 and NIST AI Risk Management Framework (AI RMF). Both frameworks, while different in their approach, emphasize the need for human intervention to ensure the responsible and ethical use of AI systems.
This post is my interpretation of the paper that was presented at the recent session of the monthly Data61 AI Adoption and Assurance Chat - “Designing meaningful human oversight in AI” (https://www.researchgate.net/publication/395540553_Designing_Meaningful_Human_Oversight_in_AI).
(the full citation for the paper: Zhu, Liming & Lu, Qinghua & Ding, Ming & Lee, Sunny & Wang, Chen & Data, & Csiro, & Australia,. (2025). Designing Meaningful Human Oversight in AI. 10.13140/RG.2.2.16624.11528)
The paper discusses the problem with the current approach to human oversight and presents practical tips for AI system developers.
What is human oversight and how is it done?
The problem with human oversight is that it is poorly defined. But, in my opinion, what make everything more complicated is our natural automation bias - a tendency to trust a machine’s output over our own judgment. How many times have you blindly followed a GPS into a non-existing road?
As a result, we may approve the system output without properly understanding it (“rubber-stamp” it).
For example, a bank’s AI system can flag your transaction as high-risk, and a human analyst, tasked with reviewing thousands of such alerts daily, automatically approves the AI’s decision and freezes the your account.
The opposite scenario is common, too: we constrain the system so much that instead of giving it a high-level goal and some freedom to explore tradeoffs and find compromises, we try to pre-program every single action it should take and thus reduce it to a rule-based automation system.
A company wants an AI chatbot to handle customer inquiries. Instead of giving it a high-level goal like “solve the customer’s problem politely and efficiently,” you program it with a rigid script that script dictates that if a customer asks, “How do I return a product?”, the bot must respond with a link to the returns page and then ask, “Did this answer your question?” It can’t handle nuanced questions like, “I lost my receipt, can I still return this?” because the rules don not cover that specific scenario. The chatbot loses its agentic quality and becomes a basic, frustrating decision tree.
The paper argues that neither of these scenarios is optimal, and that human agency and AI agency are not a zero-sum game. Collaboration of the two produces better outcomes than either could achieve alone.
How can human oversight be designed to enable this collaboration?
Two types of agency
Let’s start from the definition of agency: it is the ability to take action and make things happen on your own, to achieve a goal.
The paper suggests distinguishing between the two types of agency:
- Operative agency (AI’s capacity to generate solutions)
For example, a medical AI system generates a diagnosis.
- Evaluative agency (human’s capacity to understand, judge, verify the AI’s solution and where necessary, steer its outcomes or substitute them with alternative solutions)
A doctor does not replicate the diagnostics process.It’s not a doctor’s job to redo the AI’s work or outsmart the machine. Instead, their role is to evaluate the AI’s diagnosis. The doctor asks, “Does this make sense? Is the AI’s reasoning consistent with what a responsible human expert would do?” They check for consistency. They review the AI’s rationale, which might be a list of key symptoms and a citation of medical literature. The doctor verifies that this reasoning aligns with their own training and medical standards. They also add human context: knowing that the treatment for a rare disease is an expensive, painful, and intensive year-long therapy, they consider the patient’s preferences, financial situation, and whether they’re willing to commit to such a difficult regimen. Finally, they weigh the potential benefits of the treatment against its significant burden and decide whether it’s the most appropriate and ethical course of action, even if the AI’s diagnosis is technically correct.
It’s hard to disagree with the authors’ opinion that ‘evaluate’ is a better word than ‘oversight’ because it emphasizes the human role as active and judgmental, rather than merely supervisory or symbolic.
Evaluative agency provides accountabilty
If something goes wrong, a human is ultimately responsible. The AI can’t be held accountable in a court; the person who evaluated its output can. Besides, the human’s judgment anchors the AI’s actions to professional, ethical, and societal standards that the AI itself cannot understand. The AI can find the fastest route, but only the human can decide if that route is the most ethical or safe. These two benefits are key to responsible and trustworthy AI.
Internal vs external reasoning faithfulness
How can we evaluate a system’s outputs if we still cannot fully grasp the complex internal workings of modern AI models? Every neural network activation, every parameter adjustment, or how the model’s learned knowledge (like the concept of a “cat”) is distributed and stored within its millions or billions of parameters (the model’s memory) - trying to understand this algorithmic circuitry is not feasible at this stage of AI development, and even if it were, it would be like looking at the decisions a chess computer program makes through the prism of single calculations it makes - too many details, too complex, and not very useful for actually evaluating the decisions.
Instead, we can design systems in such a way that they provide explanations that make sense to a human - explanations based on what the paper refers to as “external reasoning faithfulness” or “plausibility”. A chess program would say, “I chose this move to control the center of the board and put pressure on the opponent’s knight”, and we would be able to evaluate this decision because its explanation aligns with established chess principles and human judgment.
Now, how do we design a system to provide such clues we can evaluate and, if needed, contest?
Solve-verify asymmetry
The paper introduces a useful concept of solve-verify asymmetry: the difficulty of creating a solution (solving) and the difficulty of checking that solution (verifying) are often not equal. This is the case at both design time and at the run time, and understanding it helps create an effective human oversight process.
At the design phase, the “solve” task is the effort required to build the AI system:
- creating system architecture
- specifying objectives
- implementing the system
- designing verification tasks and thresholds to apply across many future instances
The “verify” task is the effort to evaluate and validate that system before it is deployed:
- requirements review
- architecture and design evaluation
- testing
- other forms of verification and validation
At runtime, we look at individual instances - specific outputs of the system, specific solutions it suggests. The “verify” task here is evaluating these single outputs. Sometimes the “solve” tasks are very computationally-expensive but checking the outputs is easy; however, there are cases when the AI generates an output quickly but the human overseeing the system will spend a lot of time and effort verifying it (for example, fact-checking, reviewing for bias, ensuring content alignment with standards and so on), and verification becomes a bottleneck.
The core takeaway is that effective oversight must adapt to this asymmetry.
When design-time verification is easy
This strategy is about building in safety from the very beginning. By front-loading the verification process, you can catch potential issues before the AI is even put into use, reducing the need for constant, manual monitoring.
For example, a factory robot’s arm must operate with a high degree of precision and safety, always staying within its designated work area. The verification that it will not harm a nearby human worker is done during the design and programming phase through extensive testing, modeling, and pre-programmed safety parameters. The goal is to ensure the system is “safe by design,” making real-time human intervention in its basic movements unnecessary.
When design-time verification is difficult
This paper acknowledges that some AI tasks are too complex to be fully verified during development. In these cases, the system can be designed to provide clear, actionable information to a human operator, who can then make an informed final decision. The human acts as the ultimate checkpoint.
For example, an AI system that recommends a diagnosis is performing a highly complex task. Its accuracy can be difficult to fully verify during development because of the infinite variations in human anatomy and disease. Therefore, the system should be designed to facilitate runtime verification: it will not just give a diagnosis but also provide a confidence score (e.g., “95% probability of a benign tumor”), highlight the specific areas of a scan that led to its conclusion, add other relevant citations, and offer a detailed explanation of its reasoning (rationale traces). A doctor then can use this information to make the final, informed diagnosis.
What about subjective domains where there is no right answer?
In areas like art, ethics, or strategic planning, different people have different values and perspectives. Here, instead of having an AI system “collapse” all the diversity into a single “correct” answer where there often isn’t one, we should design AI to be a partner in a discussion. The goal isn’t to get a perfect solution, but to surface different perspectives and scenarios. This approach makes disagreement a valuable part of the process, as the AI can show you the various trade-offs and viewpoints. By doing this, the system becomes more accountable, because it forces you, the human, to actively consider these options and make a thoughtful, well-reasoned decision based on all the available angles.
Boundary of delegation
The paper authors emphasize that there is a line beyond which AI should no longer be the primary decision-maker - they call it “boundary of delegation”. In certain high-stakes fields like legal sentencing, medical diagnosis, or hiring, the final judgment carries significant ethical and normative weight. These decisions should not be delegated entirely to AI. In these cases, oversight isn’t just about checking if the AI’s output is correct. It’s about safeguarding human responsibility. The AI should act as a tool to support the human decision-maker, providing data and insights, but never fully substituting their role. The final call must remain with a human to ensure ethical and moral accountability.
3 Cs of efficient human oversight
What we need to achieve when designing the AI oversight process?
- Control (we humans can make timely and effective interventions to pause, redirect, or substitute an AI’s decision)
- Contestability (AI decisions are backed by understandable reasons and evidence, so they can be reviewed and challenged)
- Competence (oversight improves the system’s overall performance and fairness, avoiding blunt overrides that would degrade the AI’s correct outputs)
Conditions of agency and oversight
The paper refers to the conditions of agency (individuality, source of action, goal-directedness, and adaptivity) as a framework to design effective human oversight at both design time and runtime. You can read more about these conditions in another paper - Agency is Frame-Dependent
Let’s look into each of these conditions - and the practical human oversight design tips related to each of them that the paper offers to system developers.
Individuality
This condition requires a clear boundary between the AI’s role (operative agency) and the human’s role (evaluative agency).Here we need to create the blueprint for human-AI interaction where the AI should be free to work autonomously, and the human should intervene only at specific, well-defined checkpoints. Blurring these lines diffuses accountability.
Design time
- Define the system’s boundaries and set explicit handover points for human intervention.
Where does the AI job ends? Not just “The system will handle customer service” but “The system will answer customer questions related to product specifications from a predefined knowledge base. It will not handle billing disputes or refunds.”
- Add conditions for abstention (the refusal to answer a query) when the system has to flag a case for human intervention instead of guessing
For example, when the confidence score < 90% the system will signal to a human that it is operating in a “gray area.”
- Define predetermined human handoff checkpoints - where control shifts from the AI to a human.
It’s not just about a low confidence score, but about the significance of the action itself. For example, even if an AI is 99% confident, if the decision involves a financial transaction above $1 million or a critical medical diagnosis, the high-risk nature of the task makes it a mandatory human checkpoint. Here is an example of how human handoff can be implemented in MS Copilot agents:
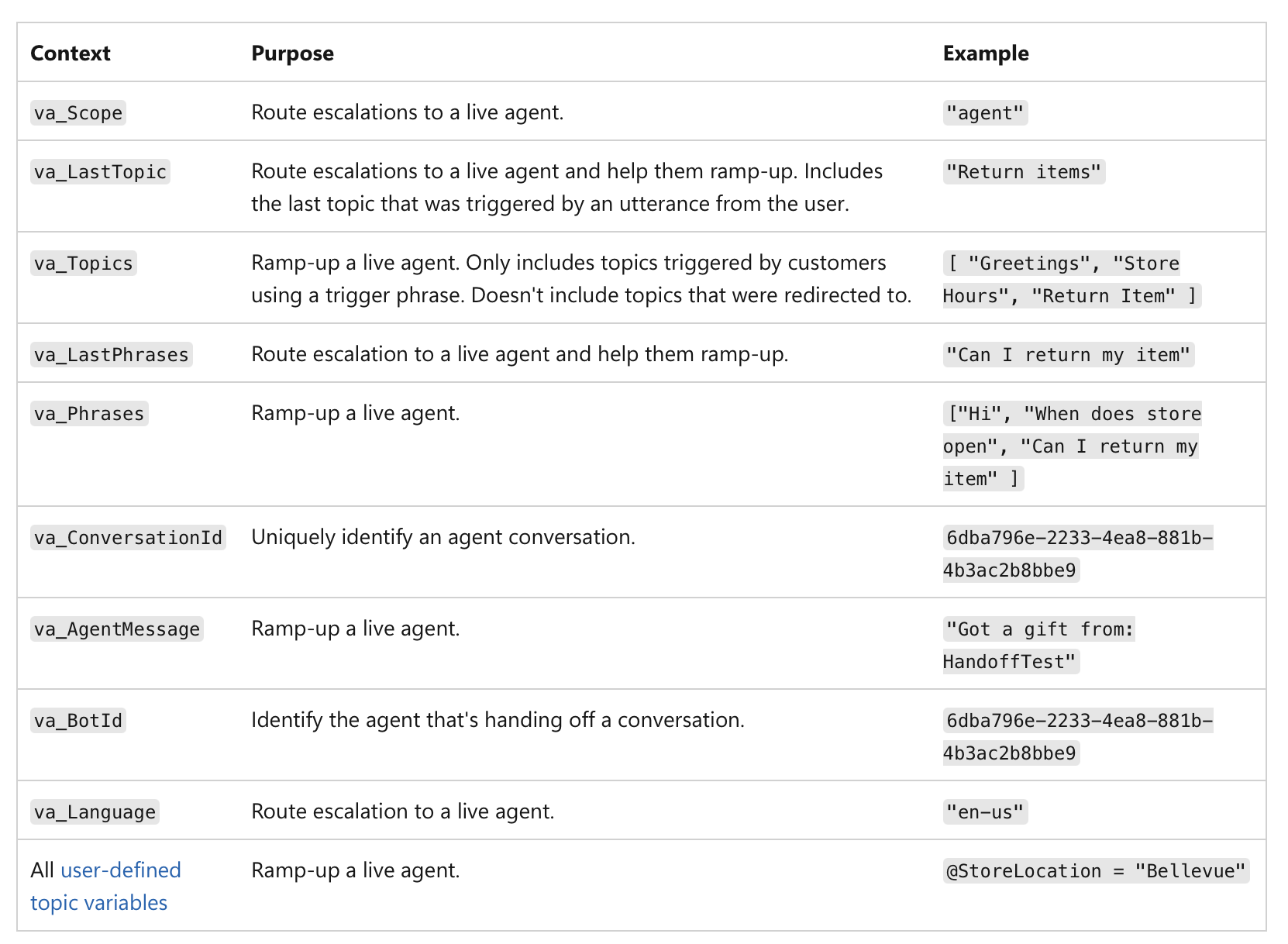 (source)
(source)
Runtime
Once the system is live, the focus shifts to logging and accountability.
- Log when control actually passes from the AI to the human.
Your system must create an immutable record (e.g. on a blockchain or a write-once database - to prevent tampering) of every handover: the log should include a timestamp, the AI’s final action, and the identity of the human who took control:
“Loan application #12345 handed over to human analyst Mary Smith at 10:30 AM due to credit score below threshold.”
This ensures clear accountability for the final decision.
The logged data can be used to create dashboards and reports for oversight - you can see how often human intervention occurs, whether the AI’s recommendations are being accepted or rejected, and who is making the final decisions. This helps us identify areas where the AI’s performance might be weak or where human processes need refinement.
Source of action
Here we trace the cause of an output. An AI’s generative process is often opaque, so trying to “co-own” it by meticulously crafting prompts may be just an illusion of control. Instead, human oversight should focus on evaluating the final output by reviewing the causal history (prompts, inputs, AI calls) (aka provenance).
Design time
-
Ensure the system can capture a complete record of its provenance through end-to-end logging (immutable and standardised for machine readability), where every step in the AI’s workflow is automatically logged and time-stamped:
- input data and prompt used
- specific version of the AI model used to generate the output
- full history of human instructions and modifications
- any external calls, outside services, APIs, databases the AI system accessed
- intermediate outputs the system generated but ended up discarding
This pre-print of “Using Blockchain Ledgers to Record the AI Decisions in IoT”, for example, discusses how this can be done in practice: https://www.preprints.org/manuscript/202504.1789/v1 Here is one example from this pre-print:
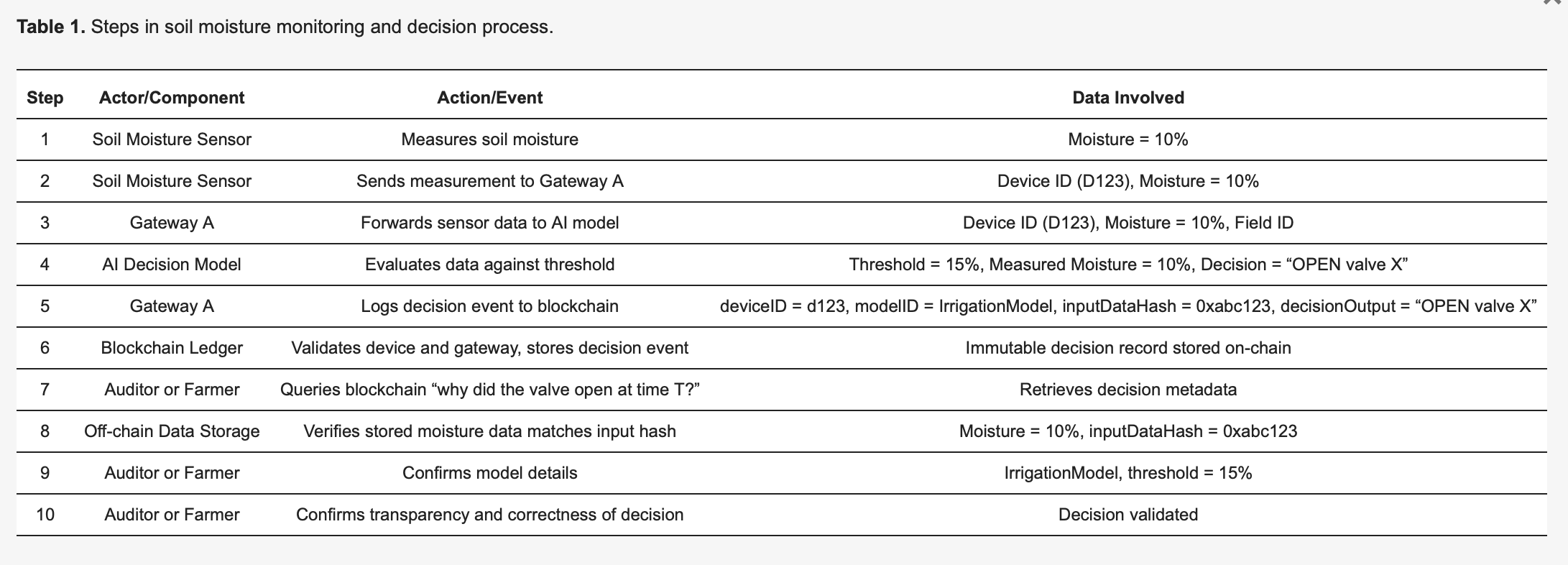
To make the methodology concrete, consider an IoT-based smart irrigation system [27], detailed in Table 1. Soil moisture sensors (devices) send readings to an edge AI model that decides whether water valves should open or remain closed. Each decision made by the AI triggers a logging event captured immutably on a blockchain ledger, enhancing transparency and auditability. As illustrated in Table 1, Sensor 123 detects moisture at 10 percent and transmits this measurement to Gateway A. Gateway A forwards the data to the AI model, which, due to a predefined threshold of 15 percent (specified by the IrrigationModelv2), determines the appropriate action: “valve = OPEN” for field X. Gateway A then prepares a transaction containing critical metadata—including the deviceID (123), modelID (IrrigationModelv2), a hash of the input data (0xabc123), and the decision outcome (OPEN valve X)—signs it, and submits it to the blockchain. Blockchain nodes verify the authenticity and permissions of Sensor 123 and Gateway A, confirm they are properly registered to field X, and subsequently store the record permanently. An event is emitted to indicate successful logging. Later, an auditor or the farmer can query “why was water released at time T?”, retrieving the detailed transaction record from the blockchain. The hash (0xabc123) from the blockchain can then be cross-referenced with off-chain stored sensor data (stored on IPFS or Gateway A’s database) to confirm the moisture reading was indeed 10 percent. Additionally, referencing the model registry, the farmer can validate that the irrigation threshold was set at 15 percent moisture, confirming the AI’s decision was correct and justified. This structured process significantly enhances transparency: every automated action is verifiable and fully explainable through logged metadata, and blockchain’s immutability ensures that neither farm operators nor device manufacturers can secretly modify decision logs.
Runtime
- Inspect the causal chain for the specific case to see how the output was generated.
- Use a visual dashboard that maps out the entire causal chain for a specific output to see the final result and every step that led to it.
When you wants to review a decision, you can pull up the provenance record for that specific case. You don’t need to understand the AI’s internal “generative pathway” (the complex math and neural activations). Instead, you check the provenance metadata to answer questions like these:
“Was the right data used?”
For example, when a doctor pulls up the provenance record, the metadata shows a list of the specific data points the AI used. The provenance record confirms the AI used patient’s full medical history, a recent blood test from 10/24/25, and an MRI scan from 10/26/25, and all data points match the official EHR. In a different case, the doctor may conclude that provenance record shows the AI accessed blood test data from two years ago, but the patient’s chart was updated with new results last week, and the AI used outdated information.
“Did the human’s prompt get accurately processed?”
The doctor’s prompt to the AI was “Analyse symptoms and recommend a diagnosis for a 45-year-old male with persistent cough and fever.” The provenance record logs the exact query the AI received. The doctor compares this to their original input and notices that the logged query shows the prompt was truncated, missing the “fever” symptom - so the AI only processed “persistent cough” which led to a different diagnostic path.
“Was the correct model version deployed?”
The provenance record may show that the diagnosis was generated by an older version of the model that should have been decommissioned because of a system error.
Here, the system clearly attributes actions to either the AI’s autonomous generation or a human’s specific intervention. This allows for clear accountability. If a bad decision is made, a quick check of the provenance log can reveal whether it was a flawed AI output or a human evaluation error, preventing the “blame-game” where agency is diffused.
Goal-directedness
The AI should handle low-level sub-goals, while humans retain authority over high-level objectives. The human’s role is to ensure the AI’s chosen path aligns with broader goals and constraints like legal requirements or fairness targets.
Design time
- Explicitly publish the high-level objectives, constraints, and trade-off rules for the AI.
The top-level, human-defined goals are made clear and accessible. These aren’t just vague mission statements; they are tangible, often numerical, targets. For a logistics AI, this could be “minimize delivery time by 15% without increasing fuel costs.” For a hiring AI, a top-level goal might be “increase qualified applications by 20% while ensuring no racial or gender bias in candidate sourcing.”
- Define constraints and trade-off rules.
Human authority is expressed through boundaries and rules. The AI should be given explicit limits it cannot violate. For example, “stay within the legal budget,” “do not recommend any action that violates privacy laws,” or “prioritize fairness over pure efficiency.” In cases where goals conflict (e.g., speed vs. cost), the human-defined trade-off rules must dictate which one takes priority.
Runtime
Here the focus shifts to monitoring and evaluation. A human doesn’t need to know every single computational step, but they can see if the AI’s general direction aligns with the higher-level objective. We can evaluate the progress at specific predefined points.
- Test whether the AI’s current output and sub-goals are consistent with those declared goals.
For example, a financial AI might be allowed to run multiple simulations to optimize a portfolio (sub-goals), but a human analyst must approve the final strategy to ensure it aligns with the client’s risk tolerance and legal requirements (top-level goals). This process allows the AI to use its “operative agency” to explore solutions, while the human retains “evaluative agency” to ensure the AI’s direction remains legitimate.
- Ensure that the system is designed to continuously monitor and report on its progress toward its sub-goals.
For a content-generation AI, this might involve it reporting on its attempts to find specific keywords or its strategy for structuring the article.
- The system should create a clear, traceable record of its decisions, including why it pursued a particular sub-goal. This record is made available to a human evaluator.
If an AI generates a biased result, an auditor can trace its path and see where it started to deviate from the fairness constraints defined at the design stage.
Adaptivity
A human can’t feasibly oversee every minor internal change an AI makes. Human oversight should be targeted at significant changes, like shifts in policy or overall system behavior. It is about creating the guardrails for the AI’s adaptive behavior.
Design time
- Set up change controls and drift monitors that detect significant behavioral shifts.
The system should be designed to version its own models and configurations to make it possible to roll back to a previous, stable version if something goes wrong.
Drift monitors are tools that constantly track the AI’s performance and behavior in the real world. They don’t just measure accuracy; they look for concept drift (when the relationship between input and output data changes) and data drift (when the input data itself changes). The monitors are set with specific thresholds. For example, a fraud detection AI’s drift monitor might be set to alert a human if its false-positive rate increases by more than 5%.
Runtime
Once the system is live, humans are not constantly watching it. They are alerted by the automated monitors, allowing them to focus their attention effectively. When a drift monitor’s threshold is crossed, it automatically sends an alert to a human team. The alert should include a snapshot of the observed behavior and the relevant data, so the human can quickly assess the situation. The system can also be pre-programmed to follow a specific protocol when a change is detected.
What do I get if I implement this framework?
This approach creates a powerful partnership where the AI system and the “overseeing” human each have a distinct, valuable role. The AI is free to use its computational power to tackle complex problems (its “operative agency”), while the human, using clear signals from the system, is empowered to make informed, high-level decisions and intervene when needed (their “evaluative agency”). The result is a “non-zero-sum” collaboration, where the combined effort leads to better outcomes than either the human or the AI could achieve alone.
How does this framework address Art.14 of the AI Act?
The framework directly addresses the requirements of the EU AI Act, particularly Article 14, by offering a practical, actionable approach to “effective human oversight” that goes beyond abstract principles. It defines oversight not as a vague obligation, but as a systematic process of designing AI to support human evaluative agency.
What does the AI Act require from AI system developers?
- “Appropriate human-machine interface tools… can be effectively overseen.”
The framework’s core principle is that the AI system itself must be built to enable oversight. The framework proposed by the paper offers fundamental design features that ensure the system’s operation is transparent and manageable for a human.
- “Aim to prevent or minimise the risks.”
The framework’s emphasis on evaluative agency directly addresses this. The human’s role is to provide the higher-order judgment that anchors the AI’s actions to professional and societal standards. This is the mechanism for preventing risks that the AI, operating with its operative agency, might not detect. The framework’s design time checks ensure risk prevention is an intentional part of the system’s architecture, not an afterthought.
- “Measures… built into the high-risk AI system.”
The framework’s entire structure is built around this requirement. The “AI Artifacts to Expose” and “System Verification Surface” for each condition are examples of measures that are “built… into the high-risk AI system by the provider.”
Individuality condition requires the system to be designed with clear handover API contracts. The Adaptivity condition requires built-in drift monitors and rollback mechanisms. These are all concrete measures implemented by the provider.
The framework also guides the provider in identifying measures for the deployer. For example, the Source of Action condition requires the provider to give the deployer a provenance dashboard, which is a key measure for the deployer to implement and use.
- “Human oversight… enabled, as appropriate and proportionate.” The framework directly translates each point of this sub-article into a design requirement.
a) “Properly understand the relevant capacities and limitations”
The Individuality and Goal-directedness conditions address this by requiring explicit documentation of the AI’s boundaries, objectives, and constraints. This provides the human with a clear understanding of the AI’s capabilities.
b) “Remain aware of… automation bias”
The framework promotes evaluative agency as a counterbalance to automation bias. The emphasis on checking the AI’s outputs rather than just accepting them forces the human to remain engaged and provides a mechanism to override the AI when necessary.
c) “Correctly interpret the… output”
The Source of Action condition ensures the AI’s output is accompanied by interpretable metadata and provenance records. This enables the human to correctly interpret the output’s context and causal chain, making a simple judgment call possible.
d) “Decide… not to use… or disregard… the output”
The Individuality condition directly supports this by requiring explicit handover points and “refuse to answer and hand over to a human” mechanisms, empowering the human to step in and override the system.
e) “Intervene… or interrupt… through a ‘stop’ button”
The Adaptivity condition’s rollback and abstain mechanisms provide the functional equivalent of a “stop” button. They enable a human to halt or revert the AI’s operation in a safe and controlled manner.
f) “Verification by at least two natural persons.”
The framework provides the tools to make this a feasible and meaningful process. The Source of Action condition’s provenance record and a clear log of all human interactions make it easy for two or more individuals to independently verify an AI’s identification. They can both pull up the same set of logged data and review the causal chain to reach a consensus, ensuring the verification is based on objective evidence rather than subjective guesswork.
Challenges
Of course, while the framework looks very promising and applicable, the paper does not ignore the common drawbacks of implementing the oversight mechanisms.
Complexity and cost
First, not all of them are simple to set up - many require significant upfront effort to design and build. You need specialized expertise to create systems that can generate structured rationales, capture provenance, or encode nuanced rules into a goals ledger. Besides, prepare for ongoing costs of maintaining the system, calibrating signals, and training human reviewers on the new processes.
Signal dependence
The effectiveness of these oversight mechanisms is highly dependent on the quality of the signals they produce. If the AI generates poor or noisy signals (e.g., inaccurate confidence scores, vague rationales, or flawed provenance data), it can mislead the human reviewer and undermine the entire oversight process.
Verification burden
While the goal is to improve efficiency, these systems don’t completely eliminate the human workload. In borderline, novel, or ambiguous cases, the human reviewer may still need to perform intensive, manual spot-checks. The paper notes that this can reduce the efficiency gains, as reviewers may need to spend a lot of time resolving abstains or contesting the AI’s suggestions. The human burden shifts from a full-scale evaluation to a detailed verification of the AI’s work, which can still be significant.
Remember: mindset shift is needed
So, it’s not enough to just say we need “human oversight.” To make it a relaity, we need to shift our mindset from simply “supervising AI” to designing AI for AI-human collaboration: redefine the human’s role as an active evaluator, build oversight into the AI design, remember about the three Cs - control, contestability, and competence, - and then you will not only be complying with regulations like AI Act - you will be creating a more trustworthy and powerful system that works with people.
Many thanks to the paper authors: Liming Zhu, Qinghua Lu, Ming Ding & Sunny Lee, and Chen Wang (CSIRO Australia, Data61) - this was a very insightful read!
